Chapter 9
INTER-Mediatorの実環境での展開
この章は、INTER-Mediator Ver.12をもとに記載しました。
INTE-Mediatorを実際にサーバー等で運用するまでの話題をこの章で扱います。具体的には、データベースとWebサーバーのインストールや運用、そして、INTER-Mediatorで作ったファイル群をどのように管理するのかなどを説明します。しかしながら、例えばMySQLの動作や設定方法の全てをここで説明するのはこのトレーニングコースのカバー範囲を超えてしまいます。データベースに関する知識は他の一般的な教材を使って習得済みであるとの前提で、INTER-Mediatorで使う場合のポイントなどを解説します。なお、筆者の新居は通常の開発はMySQLで行っているため、MySQLのみの詳細な解説となります。
9-1データベースとWebサーバのインストール
INTER-Mediatorがサポートする3種類のオープンソースデータベース、そしてFileMaker Serverについてインストールと運用のポイントを解説します。それぞれの製品の概要などは各製品のサイトなどで確認してください。なお、FileMakerに関しては、『9-3 FileMakerを巻き込む開発に関して』にまとめてあります。
MySQLのインストール
MySQLは最も人気の高いオープンソースデータベースであり、レンタルサーバーのプロバイダでも利用できる場合が多いこともあって、広く利用されています。
MySQLのライセンス
MySQLはオープンソースソフトウェアとして開発されており、GNU GPLv2と商用ライセンスのデュアルライセンスとなっています。用途によって無償で利用できるCommunity Edition(以下、「コミュニティ版」)を利用できますが、そうでなければ有償のStandard Edition、Enterprise Edition、Cluster CGE等(以下、まとめて「商用版」)をライセンス料を払って使用します。コミュニティ版を利用できる条件をまとめると次のようなものです。必須条件をいずれも満たした上で、条件1ないしは条件2を満たせば、コミュニティ版を利用できます。
- [必須条件] 開発したソフトの動作にMySQLが必要である。
- [必須条件] クラスタ、オンラインバックアップ、パーティショニング、Enterprise Monitor等商用版だけに搭載された機能を利用しない。
- [条件1] 開発したソフトを他の人に配布しない。
- [条件2] 開発したソフトを他人に配布する場合には、そのソフトウェアのソースコードを引き渡し、改変と再配布を誰にでもできるようにする。すなわち、GPLで利用する。
MySQLを前提にした開発アプリケーションを外部に対して全く公開しないのなら、[条件1]に該当してコミュニティ版を無料で使えます。また、ソフトウェアの複製や配布が伴わなければ、ソースコードを譲渡・公開することまでは強制されません。したがって、システムを一般に販売するわけではなく、コミュニティ版を入手した開発者がシステムを利用する範囲においてはGPLの適用を過度に恐れる必要はありません。
[条件2]は、解釈にもよりますが、受託開発したものについてはGPL運用しない限りはコミュニティ版を利用できる要求を満たさないと言えます。有償、無償を問わず複製および再配布の際にはソースコードも引き渡さなければいけないという点で、一般的なWebベースの業務システム開発への利用を躊躇する人もいます。GPLをそのまま適用するとしたら、開発物を複製・配布する際にソースコードを譲渡しない場合には商用版を購入して利用する必要がある一方、以下に示す例外措置とさまざまな情報を元にした解釈を元にすればGPL運用しなければならない範囲は限定的であると言えます。
まず、MySQLのライセンスドキュメントでGPLに加えて宣言されているFOSS License Exception(Oracle's Free and Open Source Software License Exception、以下「FOSS」)で、オラクルはライセンスの例外措置を定義しています。FOSSによりオラクルが規定したいくつかのオープソースライセンスのソフトウェアに関して、MySQLと一緒に利用しても、オープンソース側のライセンスは変更する必要がありません。FOSSの範囲であれば、GPLを適用せずにコミュニティ版を利用できるケースがあるということです。関連するソフトウェアを対象としてライセンスがどうなるのかを検討すると、ApacheやPHPは本来のランセンスで利用でき、INTER-Mediatorも本来のMIT Licenseで利用が可能であることは確かです。
ここで、[条件1]や[条件2]での「開発したソフト」がどの範囲までなのかということが問題になります。MySQLが主張するGPLv2では、MySQLを利用した全ての開発物を配布する際にはソースコードも譲渡すれば違反しないと読み取れる内容です。したがって、全ての開発物を複製・配布する際にはソースコードを引き渡すのが「必要である」という解釈がなされるわけです。しかしながら、FOSSを記述したサイトのQ&Aの最初の項目には、FOSS自体がMySQLのクライアントライブラリにおいてGPL以外のライセンスを可能にしているものだと説明されています。例えばPHPのMySQL向けドライバーは、MySQLが提供するライブラリをPHPから利用できるようにしたものであり、MySQLクライアントと強く結びついたものです。PHPのドライバーは明らかにMySQLを基にして作られたものであり、FOSSが宣言されていなければ、PHPのMySQLドライバーはGPLにしなければならないと言えますが、FOSSによってPHPライセンスであることを主張できます。
この点を考慮すれば、GPLの及ぶ範囲すなわち「開発したソフト」は、ライブラリ利用や完全統合といった強いソフトウェアの結びつきに対して適用され、「プロセス間通信」や「ネットワーク経由の通信」のような独立プロセス間を接続した場合には適用されないと解釈できます。したがって、コミュニティ版をそのまま使い、Apache+PHPでサーバーを組み、INTER-Mediatorでシステムを作ったときに、自分で作ったHTMLやJavaScriptのプログラムなどは、条件にある「開発したソフト」に該当せず、GPLの及ばない範囲として独自にライセンスを適用できることを意味していると読み取れます。ただし、これは記述されている事実を基に判断したことであり、Webサーバーや開発したアプリケーションに対してGPLの適用はしないと明確に書かれてはいないということをどのように考えるかにかかわる問題でしょう。
以上の解釈を元に、MySQLのコミュニティ版で稼働するINTER-Mediatorで受託開発をしたシステムを納品する場合について、いくつかの事例で考えてみます。自社で使用するシステムを開発する場合は[条件1]に該当するため、コミュニティ版を利用できます。顧客が契約したプロバイダのレンタルサーバーですでにMySQLをサービスとして稼働しているような場合は、受託開発部分にはGPL適用部分がないので[条件1]に該当し、コミュニティ版を利用できます。顧客が所有するサーバーにセットアップする場合、すでにMySQLがセットアップされているなら[条件1]に該当し、コミュニティ版を利用できます。一方、MySQLのセットアップを請け負った場合はやや難しいですが、顧客が入手したMySQLのセットアップ作業を代行するのであれば[条件1]に該当し、コミュニティ版を利用できます。一方、納品物に「MySQL」あるいは「MySQLセットアップ」という項目があり、業者側がMySQLを取得して顧客のサーバーにインストールするとしたら、クライアントライブラリも含まれるため[条件1]には該当しません。また、MySQLを搭載したサーバーとして納品する場合も最後の状況と同様です。この場合、開発した部分はGPL運用しなくてはいいものの、納品先でGPL運用する必要がある素材を渡すことになります。一般には、そのようなソースコード公開の必要がある品目を使用するよりも、商用版を購入してシステム全体を顧客が独占的に使用できる状態にする方が望まれるのではないかと思われます。
MySQLで使用するキャラクタセット
本稿を執筆時点では、Ver.8.2がリリースされていますが、プロバイダーにあるものなどを含めて、Ver.5.7〜8.2が混在している状況です。なお、MySQLにはVer.6, Ver.7は存在せず、Ver.5.7の次はVer.8.0です。Ver.5系列は、Premier Supportは遥かに過ぎ、Extended Supportの期間を過ぎていても、プロバイダ等で利用可能な状態になっている場合がよくあります。バージョンをあげて動かなくなってしまうことを嫌っての対処となると思いますが、場合によっては古いバージョンを使わないといけないことがあります。バージョンの違いでまずは気をつけなければならないことは、Unicodeサポートです。Ver.5.1でUTF-8をサポートしていますが、この時は長さが3バイトまでしかサポートしていませんでした。日本語のカナや漢字のほとんどはUTF-8では3バイトですが、スマホの普及とともにUTF-8で4バイトになる文字も、クライアントで利用できるようになってきました。代表的なものは絵文字ですが、「𥔎」(サキ;石偏に立可)などの一部の人名で使われるような漢字も含まれています。3バイトまでのキャラクタセット名が「utf8」なのに対して、4バイトまでのUTF-8の文字を利用できるキャラクタセットは別の名前「utf8mb4」となりました。これはデータベースの設定やあるいはスキーマ定義の時などに意識してutf8mb4と記述をしなければなりません。このエンコード名はVer.5.5.3からのサポートなので、入手できるVer.5.5のものでは原則利用できると考えて良いでしょう。また、バージョンごとに既定値が違うことから、以前のバージョンで動いていたビューがあるバージョンからダメになるなど、バージョン間の違いは無視できるものではありません。エラーメッセージを見ながら、必要な対処を行う必要があることは想定しておくべきです。
インストーラを利用したインストール
MySQL Community版のインストールは、ダウンロードのページから適切なエディションやOS等を選択すれば可能です。一方で、Linuxの場合は、yumやapt-get、aptitude等を使うことになります。この時、公式のレポジトリでは古いバージョンしか入手できないかもしれません。これらのコマンドによるインストール機能向けのインストーラーも、MySQLのサイトで入手できます。ダウンロードのページで、サブメニューを見ると、Yum Repository、APT Repository、SUSE Repositoryといった項目が見えます。これらのページから、レポジトリとしてMySQLが用意した最新バージョンをインストールできる箇所を追加できる仕組みを提供しています。ここでの説明を見て、Linux上でレポジトリを追加して、インストール作業をすれば良いでしょう。
リスト9-1-1は、Ubuntu Server 22での例です。ディストリビューションの中にダウンロード可能なレポジトリは登録されているので、コマンドを入れてインストールするだけです。通常は、サーバ版とクライアントをインストールします。Ubuntu 22では、MySQL 8.0がインストールされます。一般に、ディストリビューションのメジャーバージョンごとに、サポートするMySQLなどのアプリケーションのバージョンも固定化されます。もし、8.2などの違うバージョンのMySQLをインストールしたいのなら、レポジトリを追加しますが、詳細はそれぞれのディストリビューションごとに異なるので調べて実施してください。
sudo apt install -y mysql-server
sudo apt install -y mysql-clientいずれの方法でインストールをしても、データベース領域の初期化が行われ、あらゆる権限を持ったrootアカウントを自動的に作成します。インストーラーがあるものは、途中でそれをダイアログボックス等で表示するので、基本的にはそこで書き留めるか、画面ショット等を作成しておくのが良いでしょう。Ubuntu Server 22に入るMySQLだと、rootアカウント自体のパスワードは把握する必要がありませんが、MySQL自体をrootで利用するためには、root権限のあるアカウントでクライアントコマンド等を利用する必要があります。コマンドで作業しているのであれば、sudo実行可能なアカウントから「sudo mysql -uroot データベース名」のようなコマンドで、MySQLにrootとしてログインして、データベースを利用できるようになります。sudo実行のための現在ログインしているアカウントのパスワードはキータイプする必要がありますが、OSのrootあるいはMySQLのrootアカウントのパスワードは入力する必要はありません。
インストーラでのインストール後は、mysql_secure_installationコマンドを実行するようにメッセージが出てきます。一方、最近のLinuxディストリビューションでは、このコマンドの実行に相当することは自動的に終わっているようです。このコマンドを実行することで、セキュリティ上の問題点となりそうな状態を、そうでない状態にしてくれます。以下の処理を行いますが、rootのパスワードの変更以外は、するかしないかの選択、つまりYes/Noの選択です。通常はYesを選んで設定変更をすべきですので、コマンドを実行して設定を変更しておきましょう。なお、rootパスワードについては、特にVer.5.7では複雑な文字列にしなければなりません。ここで適当にパスワードを変更するのは意外に難しいので、後から変える方がいいかもしれません。
- rootパスワードの変更。Yesを選択すると新たなパスワードを要入力
- ユーザーアカウントが指定されない時のアノニマスユーザーの削除
- 別のホストからのrootアカウントによるログインを禁止する
- テスト用データベースの削除
- アクセス権設定を再度適用する(最後に念のため)
MySQL向けのスキーマはどこまで記述が必要か
スキーマ定義では、テーブルとビューを定義します。テーブルでは、テーブル名やフィールド名とその型を記述するのは当然ですが、INTER-Mediatorの動作上はそこままでほぼOKです。ただし、主キー値を示す「primary key(フィールド名)」等の記述と、検索やソートに使用するフィールドに対するインデックスは必ず作成してください。なお、主キーについては定義ファイルでkeyキーで指定でき、スキーマ上での主キーをそのまま指定することがほとんどですが、動作上は別のフィールドも指定できますし、それが一意な値なら編集もできます。その場合はkeyキーに指定する値にインデックスを作成しておきます。
一方、外部キー制約については、必ずしも必要ではありません。制約として設定しておいて、データベース上に不整合が起こらないようにすることが必要と考えるのであれば、記述しても構いません。しかしながら、実際の動作は定義ファイルのrelationキーでの指定が利用されるため、データベーススキーマ上にテーブル間の関係は記述してもINTER-Mediatorとしては使いません。通常、不整合が発生するようなユーザーインターフェースを作ることはありえないと思われるので、正しくユーザーインターフェースを作成していれば、外部キーの指定はスキーマになくてもいいでしょう。データベースの利用方法や設定については『2-1 データベースからの取り出し設定』を参照してください。
MySQLの設定のポイント
MySQLの設定ファイルと言えば、/etc/my.cnfの変更ということになりますが、実際にはいろいろなファイルで指定ができます。したがって、現在、どんなパスのファイルが使用されるかを知る必要があります。そのためには、「mysql --help」を実行します。もちろん、mysqlコマンドのヘルプを表示しますが、その中にリスト9-1-2のような記述が含まれていて、2行目のパスのファイルが順次読み込まれます。つまり、/etc/my.cnfなどのファイルが読み込まれますが、これらの順番に読み込みを全て行い、ファイルがあれば、その設定も読み込まれます。もし、複数のファイルで同一の設定対象に対する定義がある場合には、後から読み込んだファイルの内容が有効になります。/etc/my.cnfを読む限りは、このファイルはMySQLのアップデート時に上書きされる可能性があるので、自分自身の設定は別のファイルにするのが良いと記載されています。INTER-MediatorのVMは、/etc/mysql/my.cnfに実際の設定を行っています。
Default options are read from the following files in the given order:
/etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnfクライアントからの接続をするためには、ホスト接続の場合はポート番号、ソケット接続の場合はそのパスを知りたくなります。mysqlshowコマンドに--helpをつけて実行した結果の末尾に変数の値が出力されますが、その中にあるsocketやportを見ることで参照可能です。しかしながら、この場合は、my.cnfに設定がある場合には、この方法で参照できますが、コンパイル時の既定値で稼働させた時には、この方法でソケット等が確認できない場合もあります。
Variables (--variable-name=value)
and boolean options {FALSE|TRUE} Value (after reading options)
--------------------------------- ----------------------------------------
character-sets-dir (No default value)
default-character-set utf8mb4
count FALSE
compress FALSE
:
plugin-dir (No default value)
port 3306
show-table-type FALSE
socket /var/run/mysqld/mysqld.sock
ssl FALSE
:mysqlshowコマンドで参照できない場合には、mysql_configコマンドを使用します。ただし、このコマンドはWindowsでは使えませんが、LinuxやmacOSでは利用可能です。引数なしはUsage:が見えるのですが、その下のOptions:の右の [...] で示されているのは、実際に設定された値です。この値がコンパイル時に指定されたもので、ソケットやポートは設定ファイルで変更していない場合にはこの設定に従うことになります。もし、設定ファイルで変更している場合には、ここで見える値は実際には使用されていないソケットのパスになります。
Usage: /usr/bin/mysql_config [OPTIONS]
Options:
--cflags [-I/usr/include/mysql -DBIG_JOINS=1 -fno-strict-aliasing -g -DNDEBUG]
--include [-I/usr/include/mysql]
--libs [-L/usr/lib/x86_64-linux-gnu -lmysqlclient -lpthread -lz -lm -ldl]
--libs_r [-L/usr/lib/x86_64-linux-gnu -lmysqlclient_r -lpthread -lz -lm -ldl]
--plugindir [/usr/lib/mysql/plugin]
--socket [/var/run/mysqld/mysqld.sock]
--port [0]
--version [5.5.49]
--libmysqld-libs [-L/usr/lib/x86_64-linux-gnu -lmysqld -lpthread -lz -lm -lwrap -lcrypt -ldl -laio]
--variable=VAR VAR is one of:
pkgincludedir [/usr/include/mysql]
pkglibdir [/usr/lib/x86_64-linux-gnu]
plugindir [/usr/lib/mysql/plugin]設定ファイルへの記述
my.cnfファイルに記述する内容としては、キャラクタセットを「default-character-set=utf8mb4」で指定しておくのが確実です。プロセスごとに [ ] で囲ってそれ以降の行に「変数名=値」の行を記述します。例えば、[mysqld] は、mysqldつまりMySQLのサーバーに対する処理を記述します。なお、現実には同じサーバーでMySQLのクライアントも利用しますし、SQLダンプでmysqldump等も使います。これらの設定も、my.cnfファイルに記述しておくと便利でしょう。リスト9-1-5はmy.cnfファイルの一例です。実際にはもっと多くの項目を設定することもあるでしょう。ソケットのパスを変えたいような場合でも、こちらに記述をすれば、コマンド起動時にパラメーターとして記述する必要は無くなります。なお、設定ファイルへの記述に問題があると、MySQLが起動しません。その場合、/var/log/mysql/error.logなど、エラーログを確認することで、問題のある記述がどの部分かは特定できます。
[mysqld]
validate_password_policy = LOW
character-set-server = utf8mb4
default_password_lifetime = 0
sql_mode = TRADITIONAL
[mysql]
default-character-set=utf8mb4
[client]
default-character-set=utf8mb4
[mysqldump]
default-character-set=utf8mb4ここで、mysqldにある設定項目は、Ver.5.7になってからの過去のバージョンとの互換性を確保するために、よく追加されるような項目を記述しました。まず、既定値のパスワードポリシーは非常に厳しく、複雑な文字と思って作ったものでもその一部に単語として読めるものがあると排除するなど、手作業でパスワードを変更するのは一苦労しそうです。「validate_password_policy = LOW」にすれば、ルールはかなり緩くなり、8文字以上であればパスワードとして認められます。その状態で、一定以上の複雑なパスワードを管理者が責任を持って指定することで、データベースサーバーのパスワード運用は問題なくできると考えます。このパスワードポリシーを運用するために、MySQLはプラグインを利用します。MySQLのサイトのレポジトリを利用してインストールした場合はこのプラグインが組み込まれます。
Ubuntu 16.04.1の場合には標準のレポジトリからのインストールでMySQL Ver.5.7が入ります。しかしながら、パスワードチェックのプラグインが組み込まれないため、validate_password_policyの記述自体の解釈ができずエラーとなってMySQLが起動しません。そのままプラグインなしで利用するなら、validate_password_policyの記述は削除してください。
MySQL Ver.5.7.4以降は、パスワードの有効期限が360日となっています。つまり、その期間内にパスワードの変更を行わないと、セットアップした1年後くらいにいきなり接続ができなくなります。しかしながら、これは、明らかに忘れてしまいそうな設定です。「default_password_lifetime = 0」と設定すれば、パスワードは無期限に使えます。なお、Ver.5.7.11以降は既定値でパスワードの期限は無期限となりました。
MySQLはバージョンごとにSQLコマンドのエラー時の処理などが違っています。「sql_mode = TRADITIONAL」を使えば、Ver.5.6以前に一番近い状態になります。SQLのエラーが出る場合には、この方法を試してみると、うまく行く場合もあります。INTER-Mediatorは内部でSQLコマンドを生成しているため、「SQLコマンドを変更する」ためにはソースコードを変更しなければなりませんが、それは簡単なことではありません。sql_modeをTRADITIONALにしなくても原則稼働するようにチェックはしていますが、漏れがあるかもしれません。もし、生成されたSQLに問題がありそうなら是非ともバグレポートをするとともに、この設定でMySQLの動作を古いバージョンと同様になるようにして運用をしてみてください。
PostgreSQLのインストール
PostgreSQLは古くからあるデータベースで、その起源は80年代にまで遡ります。早くから標準SQLの仕様のかなりの部分をカバーした本格的なRDBとして評価を得てきました。しかしながら、2000年前後は世界的に見ればSQLの制約があってもスピードの速いMySQLへの注目が集まる一方、なぜか日本ではPostgreSQLの方の割合が海外より高かった印象があります。日本人は「標準SQLに近い」ことに価値を感じるのかもしれません。その結果、日本語での情報も古くからインターネットを中心に共有されてきました。その後、PostgreSQLのVer.8の途中くらいからはMySQLとの性能差はほとんどなくなるくらい、パフォーマンスを上げてきました。もっとも、MySQLも制限のあったSQLのさまざまな機能をサポートしてきていることもあって、結果的にこれら2大オープンソースデータベースに大きな差がないのが現状です。
PostgreSQLとMySQLの比較の上で語られることが多いのは、ライセンスです。PostgreSQLはBSDライセンスであり、PostgreSQLを使用して作成したシステムのソースコードの公開は必要なく、ライセンスを明示すれば再配布は可能です。そのため、MySQLに比べてより確実な「フリー」であるソフトウェアと認識されています。
本稿を執筆時点では、Ver. 16.1がリリースされていますが、プロバイダーにあるものなどを含めて、Ver.9系列以降が混在している状況です。macOSやWindows向けにはインストーラーを配布しているので、原則として、それを使えばOKです。ダウンロードには、ダウンロードのページから適切なエディションやOS等を選択すれば可能です。Linuxの場合は、公式のレポジトリでは古いバージョンしか入手できないかもしれません。しかしながら、ダウンロードのページにはディストリビューションごとのインストール方法が記載されており、基本的にはパッケージシステムに新しいレポジトリを追加して、そこからバイナリをインストールする形式です。インストールするパッケージは「postgresql」あるいは「postgresql-9.5」などのバージョン入りのものも含めて、データベースサーバーのパッケージだけで基本的には利用できます。サーバーだけでなく、クライアントとして動作するためのライブラリやコマンドなども一緒にインストールされます。データベースの利用方法や設定については『2-1 データベースからの取り出し設定』を参照してください。
SQLiteのインストール
SQLiteはプロセスを起動しないタイプのデータベースです。ネットワークでの共有はSQLiteだけではできませんが、データベースファイルを用意するだけでいいので、手軽に利用できることがあります。利用するためにはOSに対応したライブラリが必要ですが、SQLiteのサイトからダウンロードできます。Linuxのパッケージでは、そのままの名前「sqlite」で検索をかけてみて、レポジトリの内容を確認しましょう。現在はUnicode対応したVer.3系列が主に利用されていますが、あまりバージョン間の違いについては話題にならないくらいなので、バージョンアップで大きな違いが発生するということはあまりないソフトウェアではないかと思われます。ただし、実際にバージョンが問題になったケースとして、SQLでのIIF文のサポートです。Ver.3.32.0で対応したのですが、それ以前のバージョンはいわゆるif文をSQL内で記述できず、caseを使う必要があり、記述が長くなりがちでした。
SQLiteは「パブリックドメイン」であるとして、ライセンス契約をするという考え方は基本的にはなく、自由に利用できるとされています。ただし、パブリックドメインという考え方が受容できない状況や、どうしてもライセンス契約が必要という場合には6000ドルでライセンス契約できることになっていますが、インターネット検索しても話題にもなっていないようなので、ほとんどの利用者はパブリックドメインで使用していると思われます。
SQLiteの使用においては、データベースファイルのパスを指定するだけです。ファイルが存在しなければ自動的にファイルは作られます。INTER-Mediatorのサンプルファイルは「/var/db/im/sample.sq3」というパスを利用しています。拡張子は統一したものはなく、また、SQLite自体も拡張子はどんなものでも動作はするようです。注意が必要なのはファイルのアクセス権です。このファイルは、PHPが稼働しているプロセスのユーザーに対して読み書きの両方の権限が必要です。LinuxやmacOSの場合、Apache 2の内部でPHPは動くので、www-dataや_apache、_wwwなどのApacheのユーザーが何かをpsコマンド等で調べてみて、そのユーザーに対するアクセス権を設定します。そして、ファイルだけでなく、前のパスの例では、そのファイルが存在するフォルダー「/var/db/im」も、同様にApacheのユーザーで読み出しだけでなく書き込みの権限が必要です。実際には、ひとつのファイルではなく、複数のファイルを利用するため、フォルダーにも書き込み権限がないと、他のファイルが作成できず、データベースとしては動作しなくなります。データベースの利用方法や設定については『2-1 データベースからの取り出し設定』を参照してください。
SQL Serverのインストール
MicrosoftのSQL Serverは、Windows版だけでなくLinux版もあります。開発に利用するDeveloper版であればライセンス料が不要ですので、手軽に試用することもできます。むしろ最近は、Azure上でのデータベースとしてSQL Serverが使いやすい状態になっていることもあり、注目されているとも言えるでしょう。
Ubuntu 16 Serverだと、「sudo apt-get install -y mssql-server」でサーバー本体はインストールできます。さらに、サーバーを利用するコマンドであるsqlcmdを利用できるようにするためには、以下のコマンド入力してセットアップが必要になります。いくつかのLinuxディストリビューションについては、Microsoftの「SQL Server on Linux」というページに記載があるので、そちらも参考にしてください。
curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
sudo add-apt-repository "$(curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list)"
sudo apt-get update
sudo apt-get install -y mssql-tools unixodbc-dev
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrcこのセクションのまとめ
INTER-Mediatorでサポートされているデータベースを利用するための情報について、MySQLを中心に説明をしました。いずれのデータベースも、インストールや運用の情報は、製品に添付されていたり、インターネットで検索することができます。それらの情報を有効に活用しましょう。
9-2Webサーバーのインストールと準備
サーバーサイドには、データベース以外にPHPが稼働するWebサーバーが必要です。もちろん、適度に分散したり、あるいはデータベースサーバーとWebサーバーが別ホストといったこともあるかもしれませんが、基本は「PHPが稼働するWebサーバー」です。なお、FileMakerに関しては、『9-3 FileMakerを巻き込む開発に関して』にまとめてあります。
Webサーバーのインストールと管理
WindowsではIIS、LinuxやmacOSではApacheが最も一般的なWebサーバーです。このところ、nginxも使われ始めていますが、IISやLinuxを使う上では、最新版のこれらのWebサーバーサービスを使うことで、おおむね目的は達成できるでしょう。また、以前はXAMPPなどを使ったり、VMを使うということもあったかもしれませんが、現状ではWindowsでLinuxを稼働させる「WSL(Windows Subsystem for Linux)」、あるいはさまざまなプラットフォームで稼働するDockerをはじめとするコンテナを使うこともでき、稼働環境は多種多様になっています。
Webサーバーの管理では、「ドキュメントルート」と呼ばれるWebサーバーで公開されるファイルシステムの領域の中の一番上位のディレクトがどこにセットされているかを知ることが重要です。また、Webサーバーを稼働させるための設定がどのディレクトリにあるのかを知る必要があります。
WindowsでのWebサーバー
IISをインストールするには、Windowsサーバーの管理ツール「サーバーマネージャー」で、「役割の追加」の作業を行い、「Webサーバー(IIS)」を追加します。他に必要なサービスなどは通常は自動的に判定してインストールをしてくれます。
IISはWindows Serverの管理ツールを利用する事以外はありえないと思うので、それを使いこなしましょう。通常は、Cドライブのルートにinetpubフォルダー作られて、そこのwwwrootフォルダーがIISのドキュメントルートになっています。ルートのディレクトリの変更なども管理ツールで行います。また、ログファイルはCドライブのinetpubフィルダ内にあるlogsフォルダーの中のLogFilesフォルダーが既定値となっています。ここにW3SVCという名前で始まるファイル名で、ログファイルが作られています。エラーログなどそのほかのログは、logsフォルダー内にフォルダーで分類して作られます。
LinuxでのWebサーバー
Linuxについては、通常はOSのディストリビューションでかなり新しいバージョンのビルドが常に手に入ります。例えば、apt-getでは「apache2」を、yumでは「httpd」をインストールすれば良いでしょう。
UNIX系ではOSやディストリビューションによって管理方法が微妙に違っています。ドキュメントルートは、以前は/var/wwwが多かったのですが、最近のディストリビューションでは/var/www/htmlであることが一般的となってきています。一方、設定ファイルについては、/etc/httpdの場合と、/etc/apache2の場合があります。いずれも、そのフォルダーにあるhttpd.confファイルが主要な設定で、そのファイルから別のファイルが取り込まれる設定になっているのが一般的です。その取り込まれる側の設定ファイルに、ホスト名ごとの設定やモジュールごとの設定が含まれるのが一般的です。そこでファイルを作ったり修正すれば事足りる、という簡単な話ではありません。ディストリビューションによって最適な管理手段が違う場合があります。例えば、CentOSは「設定ファイルを変更する」ことが主要な作業ですが、Ubuntuではモジュールやサイトの有効/無効をa2enmod、a2dismodといったコマンドを使い、設定ファイルをmods-availableに用意するとともにコマンドを使ってmods-enableディレクトリにシンボリックリンクを作成し、Apacheはmods-enablesディレクトリの設定だけを取り込むといったことを行います。このようなディレクトリに設定ファイルを用意して、コマンドでモジュールだけではなく、サイトの設定(a2ensite、a2dissiteコマンド)や、あるいは設定ファイルそのもの(a2enconf、a2disconfコマンド)の有効/無効を指定します。他のOSで設定ファイルの変更に慣れていると、Ubuntuの管理方法は最初は戸惑いますが、Ubuntuでは用意されている手法を活用することが重要ですので、まずはどのような手法なのかを確かめておきましょう。
なお、ファイアウォールが最初からセットアップされていて、一切のサーバー動作ができない状態になっている場合もあります。セットアップしたけれども繋がらないという場合には、ファイアウォールで一切ポートが開いていなかったというのがよくある原因です。セットアップしたOSはもちろん、スイッチ等ネットワーク上でのファイアウォールを含めて、その状態を確認した上でトラブルシューティングを進めましょう。
macOSでのWebサーバー
macOSでは以前は「パーソナルWeb共有」として、システム環境設定からWebサーバーの起動もできましたが、Ver.10.8のMountain Lionからシステム環境設定よりその設定項目は消えました。しかしながら、必要なモジュールはすべてインストール済みになっていて、Webサーバーとして起動できます。リスト9-2-1のコマンドを入れればWebサーバーが起動し、再起動後も続けて利用できます。ドキュメントルートは、/Library/WebServer/Documentsで、設定ファイルは/etc/apache2です。ログファイルは、/var/log/apache2ディレクトリに作られるのが既定値です。
sudo launchctl load -w /System/Library/LaunchDaemons/org.apache.httpd.plistなお、macOSにServerアプリケーションをインストールすると、管理ツール上でWebサービス管理運用ができるようになります。既定のWebサイトのドキュメントルートは/Library/Server/Web/Data/Sites/Defaultですが、管理ツールを使ってバーチャルホストの追加などができるようになります。しかしながら、管理ツールで設定できる機能は限られています。さらにきめ細かい設定をしたい場合には設定ファイルを変更する必要も出てきます。最初に読み込まれる設定ファイルは、/Library/Server/Web/Config/apache2/httpd_server_app.confになりますので、ここから辿って必要な設定を見つけたり、あるいは設定を追加するファイルを探すなどします。ログファイルは/var/log/apache2ディレクトリに作られます。
Apple SiliconによるMacにラインナップが切り替わった現在、サーバ用途にMacそのものを使う機会はかなり減っています。むしろ、Macは、開発のためのマシンとして利用することが一般的になっているでしょう。そうなると、Webサーバーをはじめとするさまざまな素材は、Homebrewを利用してインストールするのが手軽でかつアップデートも素早くできて便利です。
PHPのインストール
WindowsでのPHP
PHPのインストーラに関して、まずWindowsについてはさまざまな方法がありますが、Microsoftが配布しているWeb Platform Installerを利用してPHPをインストールするのが一番確実な方法です。ただし、更新頻度が低いこともあって、求めるバージョンのものがインストールされるかどうかはやや問題があると言えるでしょう。Windows Server 2012には対応していますが、Windows 10対応についてはリリース時期が古く明記されていません。ただし、WebMatrixのページからは、PHP7がダウロードできます。MicrsoftはPHP単体をリリースしているわけではなく、他のさまざまな素材のひとつとして配布しています。そのため、ページによって得られるものが違っており、どれを使うべきなのかはなかなか判断しにくいところですが、Web Platform Installerを利用するのが一番確実と考えられます。また、PHPのページでは、IISの設定を変更しながら手動でインストールする方法も説明されています。
LinuxでのPHP
Linuxの場合はyumやaptでインストールはできますが、ディストリビューションのメジャーバージョンで入ってくるPHPのバージョンが決まってしまいます。決められたバージョンではなく、より新しいバージョンのものを入れたい場合には、レポジトリを追加する必要があります。
リスト9-2-2は、Ubuntu Server 22で、Apach、MySQLとともにPHPをインストールするコマンドの例です。PHPはVer.8.1がインストールされます。Linux上で作業するユーザは、admとsudoグループに入れておくことで、なんでも実行可能な管理者になります。Webのドキュメント等は、Webサーバの実行ユーザであるwww-dataを所有者とする一方、その中のファイルには、admグループに対して可能な限り読み書きができるように、chmod/chownコマンドでアクセス権設定を行っています。ディストリビューションやメジャーバージョンによってインストールが必要なライブラリが違ってくる可能性がありますが、後で説明するcomposer install/updateコマンドを実行したときにチェックされるので、その結果をみて不足するライブラリは追加でインストールすれば良いでしょう。
sudo apt -y update
sudo apt -y upgrade
sudo apt install -y apache2 php mysql-server mysql-client
sudo apt install -y php-curl php-xml php-gd libicu-dev php-pdo-mysql
sudo apt install -y nodejs
sudo apt install -y composer
sudo chmod -R g+w /var/www
sudo chown -R www-data:adm /var/www
sudo systemctl restart apache2macOSでのPHP
macOSでPHPを利用する場合は、Homebrewを使ってPHPをインストールします。例えば、コマンドとしては、Homebrewインストール後に、「brew install php」と入力することで最新のPHPがインストールされ、コマンドラインでphpコマンドが利用できるようになります。
INTER-Mediator Ver.12がサポートするPHPのバージョンはVer.7.4〜Ver.8.3となっています。ディストリビューション等の状況を見ながらサポートバージョンを決めていますが、PHPでも型を意識するプログラミングができるようになっており、最低7.4としているのは、そのための対処です。
PHPのモジュールとphp.iniの設定
PHPをインストールした結果を参照する代表的な方法は、PHPプロセッサで「phpinfo()」という関数をひとつ呼び出すことです。この関数はPHPの内部状態を検査して、その結果を見やすいWebページとして表示します。演習環境を起動し(『1-2 演習を行うための準備』を参照)、ブラウザーで「http://localhost:9080」に接続します。ページ内にある「その他のリンク」の「phpinfo()関数の実行」をクリックすると参照できます。

PHPをインストールした後に、このページを必ず確認します。まず、一番最初のPHPのバージョンは当然として、「Configuration File (php.ini) Path」で、各種動作の設定を記述するphp.iniファイルのパスを確認します。パスは「/usr/local/etc/php」となっているので、設定はこのディレクトリにあるphp.iniファイルを利用していることがわかります。しかしながら、そのすぐ先に、「Additional .ini files parsed」という設定もあり、他に読み込んでいるファイルもあります。これらはPHPのモジュールをインストールすると自動的に入ります。モジュールの動作を変更する場合は、php.iniではなく、その他の.iniファイルを変更した方がいい場合もあるでしょう。
そして、必要なモジュールが含まれているかを、ページをスクロールして、あるいはページ内部を検索して確認します。例えば、図9-2-2は、PDOおよび関連するデータベースのPDO用ドライバーがインストールされていることが確認できます。タイトルの文字の「PDO」や「pdo_mysql」から判断します。
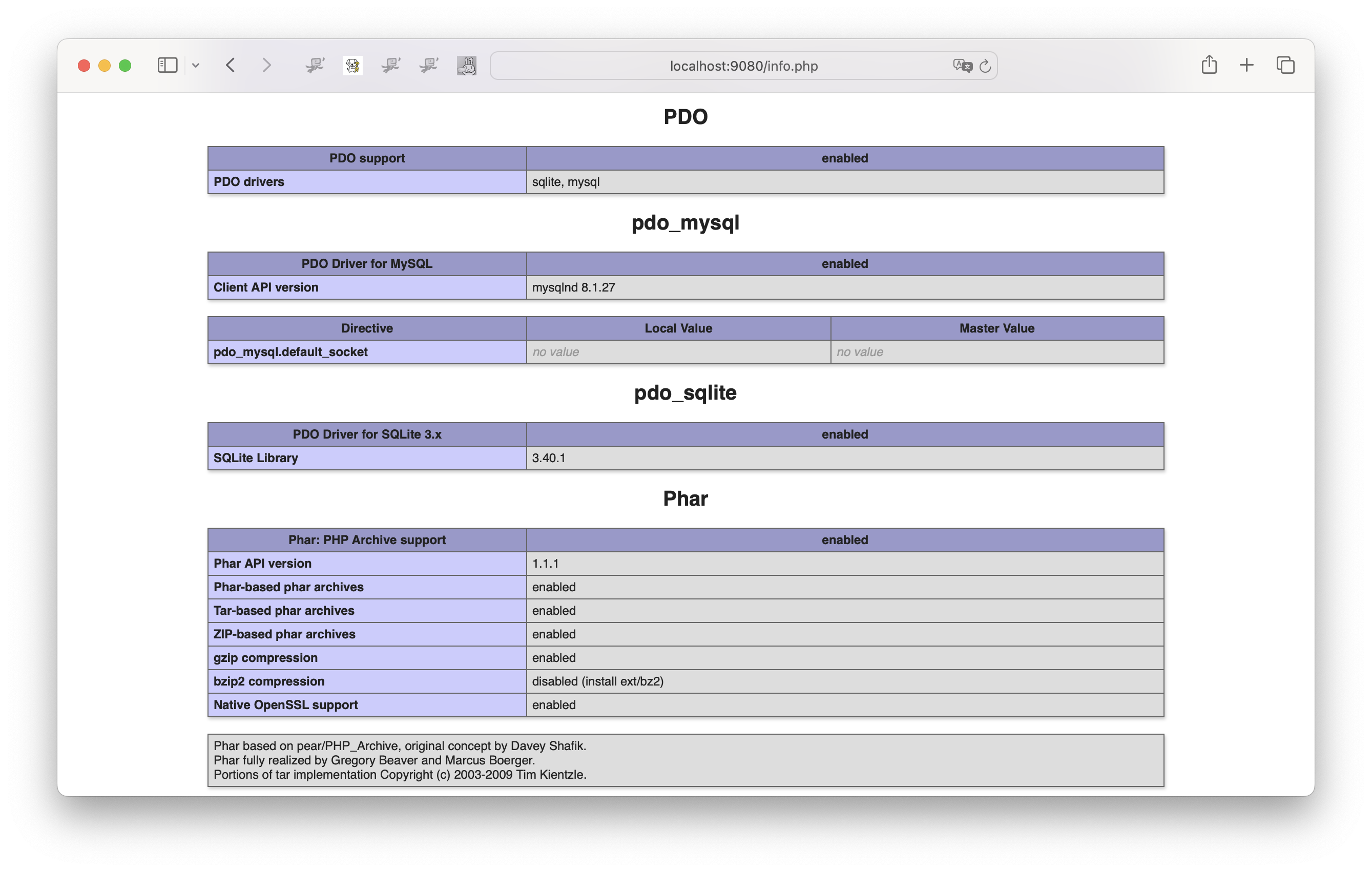
表9-2-1には、INTER-Mediatorの稼働に必要なモジュールを、phpinfo関数で表示されるページの見出しのキーワードで示しました。「必須のモジュール」は、composer.jsonに記述したもので、これらがなくてはINTER-Mediatorのセットアップが途中で止まります。「データベース関連モジュール」は、使用するデータベースに依存しますが、MySQLを使うには、PDO、mysql、mysqli、pdo_mysqlが必要になります。ただし、pdo_mysqlをインストールすると、そのほかに必要なモジュールもインストールされるので、表ではPDOのモジュール名だけを記載しました。
| 種類 | モジュール名 |
|---|---|
| 必須のモジュール | curl、intl、json、mbstring、libxml、xml、gd、exif |
| データベース関連モジュール | PDO、pdo_mysql、pdo_pgsql、pdo_sqlite、pdo_sqlsrv |
SQL Serverについては、やはりPDOのドライバーをインストールしなければなりません。PHP 7以降で利用できるドライバーが「Microsoft Drivers for PHP for SQL Server」として公開されており、Windows版と UNIX OS版のそれぞれのページに、インストール方法が掲載されています。
ファイルのアップロードを行う場合、php.iniは必ず修正をしてください。初期値では、数メガバイト程度のファイルのアップロードしかできません。表9-2-2のディレクトティブに対する設定を指定します。時間は整数のみで秒単位で指定します。サイズは、「100M」や「1G」などの補助単位も指定できます。例えば、php.iniファイルの中に「post_max_size = 500M」といった行を追加します。この時、ファイル内にすでに同一のディレクティブの設定がないかを検索してから記述しましょう。コメントも含めて、すでに「post_max_size」という単語が見つかれば、その値を修正するか、あるいはコメントの行の頭のセミコロンを削除して有効にして、右辺の値を記述します。
| ディレクティブ | 定義される内容 |
|---|---|
| memory_limit | メモリー利用量の上限 |
| post_max_size | POSTデータの最大サイズ |
| upload_max_filesize | 1ファイルあたりの最大ファイルサイズ |
| max_input_time | 入力にかける時間の上限値 |
| max_execution_time | 処理時間の上限値 |
ファイルのアップロードでは、ファイルのデータをそのままPOSTリクエストに載せます。同時に送られる情報は他にもありますがごく一部ですので、post_max_sizeギリギリまでのサイズのファイルはアップロード可能です。upload_max_filesizeはファイルのアップロード処理側で判定される値です。データは一度メモリーにロードされるので、memory_limitのサイズはファイルのサイズよりも大きくなければなりません。この3つの設定が、ファイルのアップロード処理に影響します。例えば、全部100Mに指定すれば、100M弱程度のファイルまではアップロードが可能になります。max_input_timeは、アップロードにかかる時間の上限値を指定します。これ以上時間がかかるとタイムアウトします。高速インターネットが当たり前な一方、モバイルでは極めて低速の通信しかできない場合もありますので、大きなファイルをアップロードさせたい場合には、この値を300など(つまり5分程度)大き目の値にしておきます。max_execution_timeはファイルのアップロードの時間には関係ありませんが、PHPのスクリプト処理のタイムアウト値を指定します。場合によっては、大量のデータを集計するなど、PHPの処理に時間がかかる場合もあります。その時には、この値を例えば300など(つまり5分程度)大き目の値にしておきます。
プロバイダを利用した場合のデータベースとWebサーバー
サーバーを1台分自由に使えるサービスの場合、通常のサーバーと管理は特には変わりません。一方、共用サーバー(レンタルサーバー)の場合には、Webサーバーやデータベースがすでにセットアップされた状態で利用するのが一般的です。Webサーバーにモジュール等は追加できないことが一般的ですが、例えばMySQLやPostgreSQLと一緒に使えるサービスであれば、PHP側での必要なモジュールはインストールされているのが一般的です。しかしながら、どうしても必要なモジュールが使えない場合には、プロバイダー側に要望を出して、対処してもらうしかないでしょう。
なお、レンタルサーバーの場合、Webサーバーとデータベースサーバーが異なるホスト、あるいは異なるIPアドレスである場合があります。その場合、dsnキーでは、「mysql:host=ホスト名:ポート番号;dbname=データベース名」の形式で指定します。ホスト名やポート番号は必ずサイト等に記載があります。データベースをSQLコマンドを記述したファイルから作成できる場合にはそれを使うのがひとつの方法ですが、myPhpAdminなどの管理ツールを使ってデータベースを定義する必要がある場合もあります。
安価ながら非常に古い時代に構築したままのプロバイダーだと、データベース側の文字コードをUTF-8でうまく扱えない場合もあるかもしれません。INTER-Mediatorではデータベース処理の前後に、SQLコマンドを実行できる機能があり、そのコマンドを実行させることで、正しく文字コードを処理できるような場合もありました。具体的には、MySQLでは以前のバージョンでは「SET NAMES utf8」というコマンドを実行すれば、UTF-8で処理が行われるといった対処をした時期もあったのですが、あるプロバイダではたまたまMySQLのバージョンが低く、一方でmy.cnfファイルの設定は変更できない事情があってエンコードの指定ができなかったのですが、この方法が使えました。リスト9-2-3は定義ファイルの一部です。コンテキスト定義のscriptキーは連想配列の配列で指定可能ですが、この設定だと、readつまりデータベースのクエリーにおいて、preつまりはSELECTコマンドを送る前に、definitionで定義したコマンドをMySQLに送ってエンコードの指定をしています。最近はほとんどのプロバイダでこうしたことは不要かもしれませんが、プロバイダあるいはたまたまインストールするサーバーが古いものだったりしたときにはこのような手法も考慮しなければならないでしょう。
IM_Entry(
array(
array(
'name' => 'postalcode',
'view' => 'pcode',
'script' => array(
array(
"db-operation"=>"read",
"situation"=>"pre",
"definition"=>"SET NAMES utf8"
),
),
),
),
null,
array('db-class' => 'PDO'),
false
);PHPのサーバーモード
開発しているPC/Macで手軽にINTER-Mediatorを動作させたい場合の選択肢として、PHPのサーバーモードがあります。ディレクトリにサイトに必要なファイルを作成し、加えて別途データベースサーバーの稼働が必要です。しかしながら、そこまでできていれば、Webサーバーのルートになるディレクトリをカレントディレクトリにして、「php -S localhost:8000」といったコマンドを入力します。そして、Webブラウザーからは「http://localhost:8000」とアドレス欄に入力します。すると、カレントディレクトリをWebドキュメントのルートとしてWebサーバーが稼働するような動作が行われます。引数のlocalhost:8000は、ループバックのIPアドレスでサーバー動作させて、そのポート番号が8000ということです。8000ではなくても、自由に利用できる適当な番号(9000や18000など)でも構いません。localhostで運用すれば、別のコンピューターから接続されて見えることもありません。
phpコマンドは、通常はPHPのインストール時に一緒に組み込まれます。コマンドがないと言われたら、インストール等で何か足りないのかもしれません。コマンドを起動したら、ターミナルのウインドウにはアクセスログおよびエラーログに相当する表示が行われます。何かエラーがないかを調べたい場合は、ターミナルのウインドウを眺めるなどの作業も行います。サーバー動作を止めるには、ターミナルのウインドウでcontrol+Cのキー操作を行います。なお、何もかもがApacheやIISと同じではありませんので、それぞれの利用環境に応じて読み替えるなどしてください。しかしながら、ブラウザーからページファイルを正しいパスで指定してひらけば、INTER-Mediatorの動作は確認できるはずです。
システムロケールについて
Ver.5.7-devより、システムのロケールを利用して、小数点などを取得しています。macOSのようなデスクトップ利用が主体のOSの場合は、当然ながらロケールの設定は各国に対して行われていて、日本語で利用している場合には現在のロケールとして日本語が設定されています。コマンドの「locale」が現在の設定を表示し、「locale -a」でシステムに登録されているロケールが表示されます。
$ locale
LANG="ja_JP.UTF-8"
LC_COLLATE="ja_JP.UTF-8"
LC_CTYPE="ja_JP.UTF-8"
LC_MESSAGES="ja_JP.UTF-8"
LC_MONETARY="ja_JP.UTF-8"
LC_NUMERIC="ja_JP.UTF-8"
LC_TIME="ja_JP.UTF-8"
LC_ALL=
$ locale -a
en_NZ
nl_NL.UTF-8
pt_BR.UTF-8
fr_CH.ISO8859-15
eu_ES.ISO8859-15
en_US.US-ASCII
af_ZA
:ところが、Linuxの場合だと、ロケールが存在しない場合があります。リスト9-2-5は、Ubuntu 14 Serverの一例ですが、インストール時に英語を指定したので、英語であるen_US.utf8が設定されています。全部のロケールを見ても、他にCやPOSIX等の最低限のものがあるだけです。
# locale -a
C
C.utf8
POSIX
# locale
LANG=
LANGUAGE=
LC_CTYPE="POSIX"
LC_NUMERIC="POSIX"
LC_TIME="POSIX"
LC_COLLATE="POSIX"
LC_MONETARY="POSIX"
LC_MESSAGES="POSIX"
LC_PAPER="POSIX"
LC_NAME="POSIX"
LC_ADDRESS="POSIX"
LC_TELEPHONE="POSIX"
LC_MEASUREMENT="POSIX"
LC_IDENTIFICATION="POSIX"
LC_ALL=システムがこのような状態であっても、INTER-Mediatorは可能な限り動くようにはなっていますが、できれば、日本語のロケールを追加しましょう。Ubuntuでは、ロケールは存在しないので、以下のようなコマンドを入れて、aptでロケールをインストールし、必要に応じてlocalectlコマンドで設定を行います。なお、Dockerではこのlocalectlコマンドを簡単にセットアップすることができませんので、localedefコマンドを使って設定を行う方法等があります。
sudo apt -y install language-pack-ja-base language-pack-ja
sudo localectl set-locale LANG=ja_JP.UTF-8
$ localectl
System Locale: LANG=ja_JP.UTF-8
VC Keymap: n/a
X11 Layout: jp
X11 Model: pc105このセクションのまとめ
WebサーバーとPHPが稼働する状況が、INTER-Mediatorには必要です。OSや稼働環境で色々な状況がありますが、きちんと動作して、かつ、PHPでは必要なモジュールが組み込まれていれば、問題なく利用できるはずです。
9-3FileMakerを巻き込む開発に関して
INTER-Mediatorは当初よりFileMaker Serverをサポートしてきましたが、Ver.12より「ベストエフォート対応」としました。FileMakerを取り巻く現状と、ベストエフォートに至った理由を交えて、FileMaker Serverに関する情報を掲載します。
FileMaker Serverの現状とベストエフォートの意味
FileMaker Serverは、執筆時点ではFileMaker 2023として販売されているVer.20.3.1が最新版になっています。INTER-Mediatorを作り始めた2010年ごろは、XML共有をFX.phpというライブラリで利用するWeb利用が一般的で、INTER-Mediatorもそれらを基盤として作り上げてきました。当初よりの利用方法を「Web共有による」と参照します。FileMaker Serverは一方でWebDirectとして、FileMakerで作ったレイアウトをそのままブラウザで利用できる仕組みも発展させてきました。初期の不安定な動作は今ではかなり洗練されてきており、ひとつの大きな選択肢となっています。しかしながら、Webページ自体をFileMakerで作ることによる制約とスクラッチからHTMLで記述できる方法を天秤にかけて、後者を選ぶ場合も少なくありません。そして、ライセンスに関係のないWeb共有の方が、不特定多数がアクセスする可能性のあるWebサイトでは有利とも考えられて、Web共有も、WebDirectも併存することになりました。
FileMakerはパッケージ販売からライセンス販売に比重が高くなり、さらにはクラウド版も出るなど、製品に変化が出てきました。そのような中、Web共有によるFileMakerの利用は、FileMaker Data APIに置き換わる可能性が高くなりました。Data API自体はWeb APIですが、それをPHPから使いやすくするためのFMDataAPIというライブラリも作成し、INTER-MediatorはFileMaker Data API対応を行なっています。Web共有自体はまだなくなっていないのですが、「いつかは無くなるかもしれない」という危惧があり、Web共有からData APIへのシフトをINTER-Mediatorでは行いました。ところが、FileMaker ServerのLinux版では当初Web共有が利用できなかったものの、その後に利用できるようになるなど、Web共有自体はまだ無くなる気配はないというのが実情です。
Web共有とData APIは全く異なるインターフェースなので、それを利用する側のINTER-Mediatorは「それぞれの手法」に対して対応が必要になります。つまり、メンテナンスタスクがこのように増えたのです。一方で、Web共有時代からの問題点として、高い負荷に対応できないということがあります。少ないアクセスなら良いのですが、アクセスが集中するような場合にサーバが応答しない、そして最悪はサーバが落ちるということがあったのです。加えて、Data APIは無制限に接続できるわけではなく、サーバのライセンス数までしかコネクションは設定できないので、不特定多数が利用し同時アクセスがそこそこあるようなWebサイトにはあまり向かないということもあります。
FileMaker Serverのそうした状況を鑑みると、FileMakerを使いたいけどもWebも重視するという開発は、結果的にESSを利用するのが現状の仕組みの上では最適と考えられます。例えば、MySQLやPostgreSQLをバックエンドとして使い、INTER-MediatorつまりWeb側は、これらのオープンソースOSSを使うのです。そして、それらのデータベース側のテーブルやビューをFileMaker Serverで参照して、FileMakerクライアントにサービスを提供できるようにするわけです。全データをMySQL等に置く方法もありますし、必要に応じデータをコピーして運用するなど、ニーズに応じたダブルデータベース運用のための設計は必要ですが、FileMakerにとっても、INTER-Mediatorにとっても、ボトルネックの解消にはなります。もちろん、そうなると、INTER-Mediatorの側はFileMakerを直接利用するのではなく、MySQLやPostgreSQLを使うことになり、結果的にはPDOベースでの運用になります。
このような状況を踏まえ、2023年にVer.12への開発に入る段階で、FileMakerのWeb共有はData APIに対するサポートは「余力の範囲」で行うことにしました。バグ等があれば対応はしますが、新しい機能等への対応や、テスト等へのサポートの優先順位は低くなります。つまり、サポートをやめるわけではありませんが、実運用を行うことまでの配慮は行き届かない可能性が高いというところです。これが、ベストエフォート対応の意味です。
FileMaker Serverのインストールと設定
FileMaker Serverは、クラウド版を利用するか、サーバ機にインストールするかの選択肢があります。クラウド版はサーバ管理が不要という一方で、2023年に事実上の値上げがあって、オンプレミスとの価格差が気になるレベルになってしまいました。オンプレミス版はサーバ機を用意し、FileMaker Server自体のインストーラーを使ってインストールすれば基本的にはうまくいくはずです。しかし、インストールしようとするターゲットマシンの状況に応じてさまざまな注意点があります。
FileMaker Serverは、Ver.15や16のあたりは、インストーラの動作が不安定で、インストールに失敗することもよくありました。しかしながら、19あたりから問題点はおおむね解消されています。しかしながら、対応OS等の情報、インストール手順の確認など、バージョンが変われば色々な点が微妙に変わっているので、きちんと調べてからのインストールをお勧めします。
INTER-Mediatorは、FileMaker ServerのカスタムWeb機能のひとつであるXML共有、あるいはFileMaker Data APIを利用します。XML共有はサーバからなくなるのではないかとも目されていますが、一方で、搭載されなかったLinux版のFileMaker Serverでも使えるようになるなど、まだ現役で使える機能との認識はあるでしょう。以前のINTER-Mediatorは、FileMaker Serverとの通信にFX.phpを使用していたためXML共有のみで稼働していました。データベースの利用方法や設定については『2-1 データベースからの取り出し設定』を参照してください。
FileMaker Serverのインストール方法については、マニュアルを参照してください。マニュアルにはしっかり手順は記載されていますし、よくあるトラブルはファイルメーカー社のサイトで検索すれば、見つかります。また、インターネット上での各種コミュニティでも情報があるので、トラブルに対する対処は何らかのヒントはあるはずです。ここ数年の動きで言えば、Linux版のサーバの発売や、Dockerでの稼働が確認されるなど、対応OSの拡大がありました。一方で、Claris Studioを大々的に押し出す一方でなかなか発売されないなど、FileMaker製品のラインナップの将来像がぼやけてしまっているということもあり、判断の難しいプラットフォームになりつつあります。
FileMaker ServerでのWebサーバーとPHP
FileMaker Serverをインストールするとき、PHPを使用する上で、WebサーバーやPHPをどのようにすればよいかという問合せが多くあります。以前のFileMaker ServerにはPHPがインストールされていて、即座に使える状態ではあったのですが、バージョンの問題などは当時は考慮が必要だったりしました。しかしながら、FileMaker 19の時代に、PHPの組み込みを行わなくなりました。FileMaker Serverが稼働しているサーバ側でどうしてもPHPを動かしたいのであれば、自分でセットアップするしかありません。現状で最も管理がしやすいのは、FileMaker Serverとは別に、PHPとWebサーバが稼働するサーバを立てて、そちらでINTER-Mediatorを稼働させるということです。もちろん、その間は、ネットワークでやり取りをするようにします。FileMaker Serverが稼働するサーバ上でPHPも稼働させる方法は、Claris Communityにある「FileMaker Server インストーラへの PHP 添付の廃止について」というドキュメントで公開されています。
このセクションのまとめ
現状、FileMakerを巻き込む開発で、INTER-Mediatorを利用したWebサイトを統合するには、FileMaker ServerはESSで運用して、実データをMySQLやPostgreSQL等のPDOで対応しているデータベースに置き運用することが、自由度やパフォーマンス等を含めて考えての最適解となります。
9-4INTER-Mediatorを利用する開発プロセス
データベースとWeb/PHPをセットアップした状態で、INTER-Mediatorを利用したソリューションを構築することができるようになります。ページファイルや定義ファイルの作成方法は、本書で説明してきた通りですが、ここでは実際の開発作業に入るまでの設計に関することをまとめておきましょう。
開発プロセスについて
システム開発のプロセスは、各社あるいは各自でさまざまな手法が採られていることもあり、一般的には特定のプロセスに依存した仕組みをフレームワークに取り込むということは行わないと思われます。しかしながら、業務分析を行い、システム化する範囲と内容を定め、それを実装できる形式で記述し、実際に実装してテストするという、抽象度の高い世界から実際の開発タスクにまで徐々に抽象度を下げていく手法は、ほとんどの場合踏襲するルールと考えます。その意味で、INTER-Mediatorを使った開発では、どのような流れで進めることができるのかを紹介しましょう。ここで紹介する方法は、エンジニアでないような方が、何かの業務でWebシステムを作りたいと考えたとき、INTER-Mediatorを使えばどのように進めることができるのかを紹介します。想定する開発者は、HTMLでページを作成できるものの、プログラミングについてはちょっとかじった程度とします。つまり、システム設計のプロが行うような本格的・包括的な手法ではなく、普段は会社の業務を行っているような方でも行えるような手法を紹介します。
システムへの要求をまとめる
本来はまず業務分析から入ります。業務分析は現実にはかなり困難な作業であり、専門家でなければ十分にこなすことはできません。現場の皆さんの場合は、シンプルに、「誰が」「何をする」ということを、言葉で記述して、明確化することで、システムの要求を記述することから始めましょう。「誰が」「何をする」という考え方と、「誰にとって」「何ができる」という考え方もあります。まずは、やりたいことをリストアップします。ここで重要なことは、「文字として書く」ことです。頭の中で考えたり、話し合ったりするだけではなく、記述をしましょう。そうしないと重要な項目を後から忘れてしまうなど、欠落の多い要求定義しか残りません。
一方で、システム化したい作業があるからシステムを作るということもあります。例えば、部署内で共有化したい情報をExcelのワークシートにしてサーバーに入れて使っているけれども、2人同時に更新したり、手元にコピーを作って作業した場合には古い情報を見て作業することになり、2人の間で情報の不一致が生じてしまう問題などが起こりえます。これをシステム化して問題解決したいということがあるでしょう。その場合、ワークシートが作られているので、業務の分析がすでに行われていて、一定の範囲で電子化されていると言えます。その場合は、「現在、このようなワークシートで作業している」という結果からスタートすることができます。
まずは頑張って思いつく情報を、例えば次のように、「記述」をします。もちろん、必要なら作図をしてもいいでしょう。すでにワークシートができている場合でも、そこで展開されている作業をひとつひとつ洗い出すことで、要求の記述を進めます。
- 現状理解
- 時々、部で商品紹介の無料セミナーを開くが、Webで告知はするものの、その参加受付が電話やメールで煩雑になっている。Webで参加申し込みできるようにしたい。
- 当日に、受け付けでは、印刷した参加者一覧を見ながら、参加登録した方かを確認して入場してもらっている。
- 参加者の名刺をいただいていて、後からコンタクトする場合もあるが、輪ゴムで止めて担当者の引き出しに眠っているのが関の山である。
- 必要な仕組み
- 参加希望者がWebで申し込みできる。その時に、氏名、所属、電話番号、メールアドレスを聞きたい
- 参加希望者には、申し込みを受け付けたことを確認メールで送付したい
- スタッフが、申し込み状況と申し込み者一覧を随時確認したい。最終的には名前のアイウエオ順で印刷する
- 懸案事項
- コンタクトを取っても良いかどうかをどこでたずねるか?
- 後々の営業を考えれば、属性を聞くべきか?
- 定員を設定して、定員を超えてしまった場合は申込受付を止めるか、補欠として受け付けるようにすべきか?
しかし「誰が」と言われても結構迷います。もちろん、「事務担当の山田さん」「事務担当の田中さん」がいずれも、「入金を受け付けて記録する」という作業をして、この2人が同一の作業を行うような状況では「事務担当者が」「入金を受け付けて記録する」ということを記述するだけで十分かもしれません。つまり、事務の担当者の数だけ要求の項目を書いても無駄なだけです。一方、それだったら、「誰が」というのは、「全部、『従業員が』になる」というは逆に広すぎないかをよく考えましょう。社長から末端の社員まで、皆が同じ作業をしていますか? していない人、役割が違う人がいるかもしれません。そこに注目して「誰が」をうまくまとめて「何をしている」のかを考えます。
「何をするか」は要求の記述ではさらに難しいものです。しかし、ここは考えすぎず、「なるべくひとつのこと」を「数多くピックアップ」しましょう。「何をする」かについて記述したことは、おそらく分類できるかと思います。つまり、小さな作業に分割されていれば、それをまとめて大きなひとつの作業を定義できるでしょうし、逆に大きさな作業を小さな作業に分割するという流れもあります。これらは、思いついた「何をする」をともかく記述して、分類していく作業を行いましょう。「入金を受け付けて記録する」というのは、もしかして「入金の受付」と「入金の記録」に分離できるかもしれません。入金は、銀行振り込みなら、受付処理は、「通帳記入(オンライン確認)」「前回確認日時以降の入金を調べる」「記録すべき入金かどうかを判断する(判断基準を明示)」などの作業に分解されているでしょう。また、クレジットカードであれば処理が違っているかもしれません。「入金の受付」は、もしかするとシステムを作ってやらないといけないようなものではなく、通帳やオンラインバンキングのアカウントがあればできてしまうかもしれません。しかしながら、その後の「入金の記録」は自社のシステムに記録したいとします。このようなシステム化する業務としない業務を細部で検討が必要になります。ここで、システム化する部分を細かく検討するのは当然ですが、しない部分も検討しつつ、どこかで線をきちんと引かなければなりません。これを大まかに考えるのは間違いの元で、ある箇所をシステム化対象を外してしまったために、別の作業がより大変になってしまうかもしれません。線引きはざっくり考えがちですが、比較的小さな単位に分割して検討をした上で、対象外と決定し、設計期間中は可能な限りその決定が間違っていないのかを検証しながら進めるべきです。
こうした業務の詳細化を進めるとき、「どのような」ということもやはり思いつくでしょう。それも記述しましょう。「どのような」には、「一覧から選択する」といったシステム化に直結するようなものや、「直近の10件の内容を一覧表示する」といった付帯的な表示物を指定するものなどさまざまなものがあります。また、「素早く処理を終える」といったいわゆる非機能要求もあるでしょう。こうした思いを全て記述します。
一般的なモデリングでは「なぜ」を重視します。特に要求を記述するときには、なぜを明確にします。しかしながら、そのレベルでのモデリングは専門家でもなかなか難しいものです。ここでは、要求をまとめる作業をともかく進めていただきたいので、専門家ではない方やモデリングに慣れていない方は、「なぜ」の答えとなる記述を深追いせずに、後回しにしましょう。業務内容を検討する中で、要件がスムーズに列挙でき、記述できる範囲内で、ともかくそれを書き下していくことをお勧めします。
本来、こうして考えた結果は、UMLのユースケース図で記述するのが、業界標準的な手法ではあります。しかしながら、ルールに従ったダイアグラム作成は、やはり専門的な知識とトレーニングが必要です。また、システムに対してさせたいことを記述する「要求」を基にして、システムが何を達成しなければならないのかといった「要件」の記述に進むのが、システム開発の一般的なプロセスでは提唱されています。しかしながら、要件が重要になるのは比較的大きなシステムであり、要件の記述には技術的な知識が必要です。状態遷移を伴うプロセスの場合は、一足飛びに「要求を満たすユーザーインターフェースを作る」ステップに進んだほうが効果的な場合もあります。イメージがつかみやすくなりますし、そのプロセスで必要な要求が明確に見えてくる、といったメリットもあります。例えば、電話番号はハイフンを入れた状態で入力してもらうのか、そうではないのか。もし、ハイフンなしで入れさせるのなら、そのやり方が自明となる入力フィールドの配置はどうすればいいのか、が見えてきます。全ての開発がこうした流れでできるわけではありませんが、それほどの複雑な仕組みは要求されないことも比較的多いので、まずはシンプルな手法を理解するようにしましょう。現場レベルで要求定義の作業においては、やはりExcelのワークシートに、思いついたことをともかく記述する方法が手軽です。ワークシートだと、分類や階層化などのアレンジもしやすいでしょう。また、ともかくキータイプすればいいので、記録もされやすいです。
ページ単位の設計
Webサイトは、「ページ」あるいはひとつのHTMLファイルで表現される範囲が、設計上、ひとつの重要な塊になります。前述のシステム要求をまとめるうちに、ある一定の範囲の作業をまとめたひとつのページが見えてくるのが一般的です。ひとつのページには、同時あるいは連続して行う作業を実現するためのテキストフィールドやボタンなどが含まれているというのが一般的な形態でしょう。ただし、1ページ範囲があまりに多い場合には、処理のレベルごとに要求をまとめ、複数のページに展開して実現することになるかもしれません。一方、同一の前提条件で行われる作業は、複数の作業をひとつのページにまとめたほうが分かりやすく、かつ操作しやすくなります。例えば、会員登録ページで住所、氏名、生年月日、電話番号を入れるとともに、本人確認書類をアップロードしてもらいたい場合などが良い例でしょう。住所氏名を入れるページと、本人確認書類のアップロードのページを別々に作ると、入力時の作業も煩雑で分かりにくいものになる上に、それを確認する担当者の作業も煩雑になります。したがって、これら一連の作業をひとつのページにまとめます。つまり、前提条件を揃える仕組みを共通化することで、開発効率を高めたり、ユーザーインターフェースを分かりやすく、かつ使いやすくすることができます。
ページへの分割、あるいは1ページの識別は、画一的に考えないで、柔軟に考える方がいいのですが、こちらは「デザイン」的な意味での慣れは必要です。そして、ペーパープロトタイピングと呼ばれる紙にページのデザインを描いて、実際に指で触れるなどして実感を見ながらページレイアウトを考える方法や、ワイアフレームグラフィックスのツールを使ってページを設計する方法などがあります。さて、INTER-Mediatorでの開発の場合はどうでしょう。この場合はここでページファイルの作成を始めるのが得策です。ただし、最初はデータベースの連動を考える必要はなく、ページにどんな種類の情報が、どんな風に見えてほしいのかということを、形に表すという意味で、ページファイルというよりも実際に画面表示できるHTMLファイルを作り、それを利用者がブラウザーで表示してみて業務の流れを実体験できるようにしてあげましょう。こうすることで、具体的な問題点や、注意すべき点を露わにします。「セミナーの出席者リストを作る」という作例では、例えば、次のようなページをプランすることになるでしょう。ページのデザインを考えながら、ページのデザインに直接出てこない注意点(図中の「郵便番号から自動的にある程度の住所入力を行う」など)は、要件定義と同様にどこかに記述することを心がけましょう。
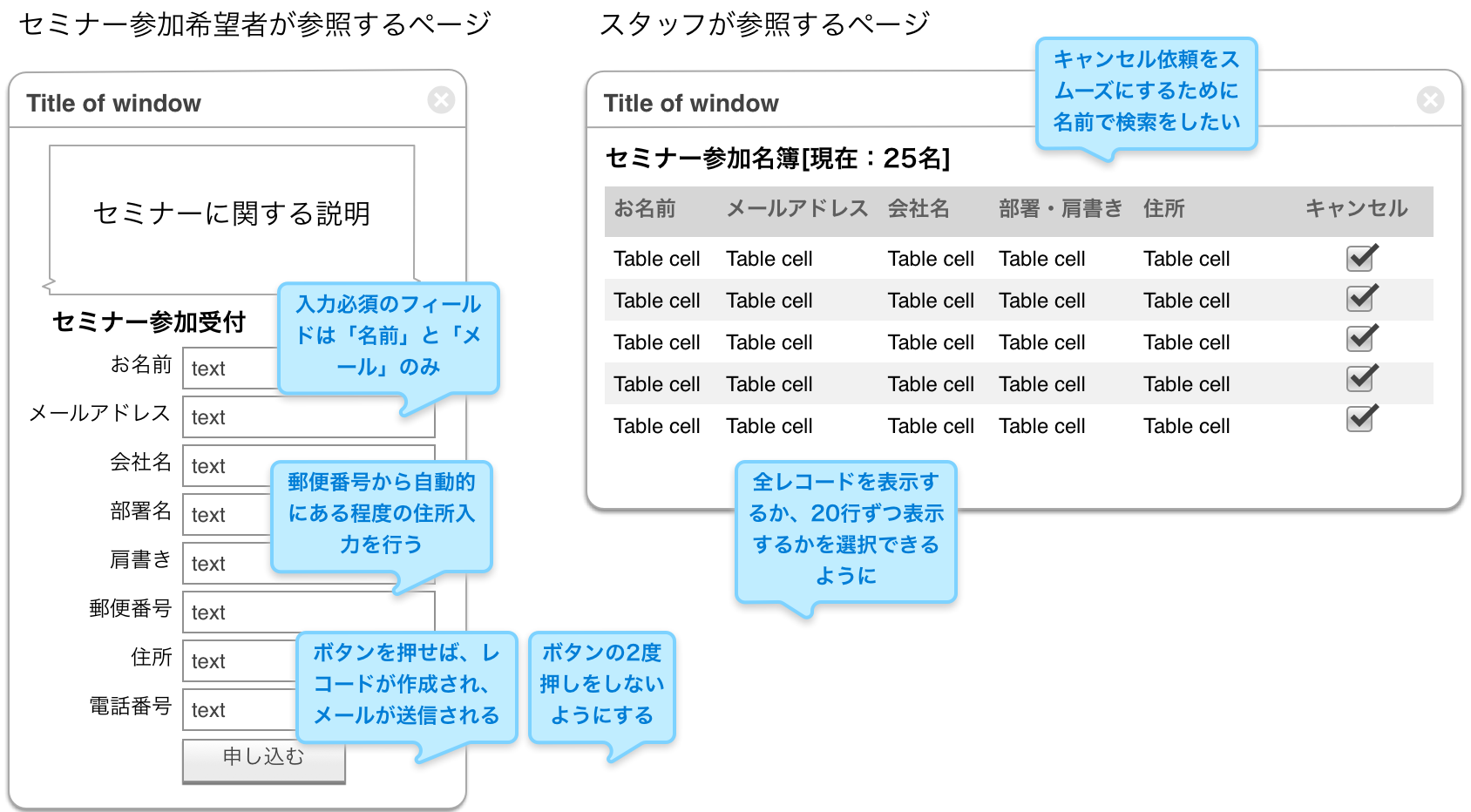
最近は、シングルページアプリケーション(SPA)として、見かけ上複数のページに見えるものの、実はひとつのHTMLファイルで実現するような仕組みのアプリケーションがあります。もちろん、INTER-MediatorはSPAの作成に対応しています。SAPは実装の手法のひとつであり、このセクションで説明しているページは、SAPにおける1ファイルの意味ではなく、利用者が見えるページのことです。
ここで、ページ内に配置するそれぞれの要素は、要求定義で抽出した各項目を配置していきます。よく使われる手法のひとつを紹介すると、要求の定義項目が確実に実現されているかをチェックするために、要求の項目に番号をつけて管理する方法があります。ともかく、業務洗い出しで出てきた必要な要素はもれなく配置していきましょう。もし、要求定義にないものがページ上にあった場合は、要求として漏れていたということになります。要求の記述そのものが曖昧なために、ページにできなかったということもあります。可能であれば、要求に戻って気づかなかった要素を追加して改めて検討します。
一方、要求の定義にあるものがページ上で登場しない場合はどうすべきでしょうか? もちろん、それは何か問題があります。例えば、テキストフィールドを忘れていては、そのデータは変更できません。しかしながら、本質的に実現できない要求を記述している場合もあります。例えば、「荷物が到着したときに日付が自動的に入力される」という要求があったとします。そのためには、例えば宅急便のサイトの情報と連動したり、あるいはサイトから荷物の状況が得られるようにあらかじめ準備すればできると思いがちですが、他のシステムとのやりとりは難易度が高いですし、仮に機能上できるとしても、自分のシステムのデータベース内で整合がとれた状態でデータのやり取りを実現するのはかなり大変です。場合によっては、システム稼働開始前と稼働後ではデータの形式が異なってしまっており、うまく統合できないかもしれません。場合によっては既に大量のデータが蓄積されているかもしれません。そのような場合は無理に自動化、統合化を図ろうとせず、単にテキストフィールドを用意しておいて、手作業で入力していくのが最も確実で早いという結論になるかもしれません。
ページを検討している時には「こういうことをやりたいけれども、ページとしてどうなるのかさっぱり分からない」ということもあるでしょう。この場合は、やはり専門家にまずはヘルプをお願いし、要求の上での過不足を見極めた上で実現可能な手法を考えてもらうのがいいと思われます。業務の流れを変えないと、システムとして実現しづらいということもあるかもしれません。
コンテキストの抽出とスキーマ定義
ページファイルを作ると、結果的に、必要なコンテキストは抽出されていると言えます。ユーザーインターフェース上でのデータの塊は、コンテキストに含まれるレコードの現れであると考えることができます。そして、レコードの「繰り返し」になる場所と、レコードと別のコンテキストのレコードが「1対多」になる場所を特定して、ページ内のひとつのコンテキストを展開する場所の割り出しを行います。そして、それに対応するコンテキストを定義しつつ、データベースに必要なテーブルを割り出してスキーマを定義します。
例示している「セミナーの出席者リストを作る」という作例に戻って考えてみましょう。スタッフが参照するページの様子を見ると、「参加者」というテーブルからの複数レコードのコンテキストが表示されているということになります。同様の情報が参加者のページにもあるので、参加者のページも同じテーブルを基にしたコンテキストであれば良いと考えます。そして必要なフィールドは、名前、メールアドレス、会社名など、参加希望の登録フォームのページの項目があれば良さそうです。例えば、一般的なSQLであれば、次のようなCREATE文でテーブルを作れば良いでしょう。そして2つのページとも、このテーブルをコンテキストとして利用するコンテキスト定義を記述することになります。型は可変テキストかTEXT型が無難でしょう。最大桁数がどれくらい必要かは、過去のデータなどから検討します。キャンセルしたかどうかは数値で記録することにし、例えば「1」はチェックボックスがオンでキャンセルしたことにし、そうでないデータならチェックボックスはオフでキャセルしていないことにします。
CREATE TABLE attendant (
attendant_id INT PRIMARY KEY,
cacel INT,
name VARCHAR(32),
yomi VARCHAR(32),
mail VARCHAR(64),
company VARCHAR(64),
section VARCHAR(64),
title VARCHAR(64),
zipcode VARCHAR(7),
address TEXT,
tel VARCHAR(20),
);このテーブル定義、そして想定しているユーザーインターフェースに限れば、コンテキスト定義として次のようなものを用意すれば目的のものが作成できるのではないかと思われます。参加申し込みのページも、参加者一覧のページも、どちらも同一のコンテキストで可能ではないかと考えられます。スタッフが見る参加者一覧のコンテキストとしては、attendantテーブルを表示しつつ、名前のフリガナでソートされており、さらにキャンセルした参加者が含まれていないようなものとなります。そのため、sortおよびqueryキーによる設定を追加しました。
name: attendant
view: attendant
table: attendant
sort: [field: yomi, direction: ASC]
query: [field: cancel, operator: !=, value: 1]通常、専門家がこうした作業を行うときには、業務分析、そして要求に応じて、まずはスキーマを設計します。実はこうした作業はなかなか難しいのですが、専門家がこういったことができるのは、Webページやそこでのコンテキストについて、実物がなくてもおおむね正しい判断ができるスキルを積んでいるからであると考えられます。むしろ、業務と要求が実現できるようなデータ記録の仕組みを抽象的に考えることで、言い換えれば「どんな場面でもうまく動く」ことを目指します。そして、分析がしっかりなされたスキーマは、要求が後から追加されてもそのスキーマで運用できる例もたくさんあります。データベースを定義し、その上で動くプログラムを作るという専門家を投入するワークフローが展開でき、実際にうまく運用できれば効率良くシステム開発が可能です。
しかしながら、専門家ではない方が、いきなりデータベースのスキーマを考えるのはかなり大変です。まずは、ページを考えて、その内容からコンテキストを抽出し、そのコンテキストに必要なテーブルを用意するという流れの方がうまくいくと思います。それでもテーブル設計では難しい問題が頻繁に発生します。専門家ではない方で、自信がない方は、要求定義、ページのモックアップを見せた上で、スキーマとして正しいのかどうかを判定してもらうということも必要かもしれません。
設計内容のレビューとイテレーション
ここまでは、「思いついたことを要求定義として記述」して、それを基に「必要な画面設計」を行い、その結果から「コンテキストとその基となるテーブルの抽出」を行いました。細かなルールは特に定めないで、直感的に作って行った流れかもしれません。しかし、ここで一度、じっくり観察をします。「セミナーの出席者リストを作る」という点ではこれだけでなんとかなりますが、セミナーが終わってしばらくして次のセミナーが開催されたらどうなるでしょうか? 参加者の項目を全部キャンセルして、再度同じことを最初からやり直す、という単純な方法もありますが、これはとても無駄の多いシステムになってしまいます。また、セミナーがたまたま2日連続で発生するようなとき、このシステムはうまく働くでしょうか? 参加者も、スタッフも「どちらのセミナーか」ということをどこでどう区別させるのでしょうか? ではどうするかというと、結論としては、セミナーの実施日をフィールドとして持つ「セミナー」テーブルを作ることが最良の対策と考えられます。
最初の要件には「セミナーの日程」ということに明確な記述がありません。強いて言えば「当日」などと記述されているあたりが落とし穴だったと思われます。実際こうした要求はシステム化する場合の最もあいまいな「抜け」となってしまいます。このままではデータベースのどこにも日付の情報がありません。つまり、attendantテーブルを探っているとき、ある参加者がいつのセミナーに参加したのが分からないのです。では、attendantテーブルに「セミナー日」のフィールドを追加するだけで問題は解決するでしょうか? また、シンプルに出席者を集約したいだけであれば、それでも機能しないわけではありませんが、例えば特定の日に実施されたセミナーの参加者をリストアップするのに、検索条件として日付を正確に入力しないといけないなど、使い勝手が悪くなりそうです。そこで、セミナー日や実施時間、あるいは場所なども含めた、「セミナー」という存在を意識します。そうすると、1回のセミナーに複数の参加者が存在することになり、ここでテーブル間の1対多の関係が見えてきます。例えば、テーブルとしては次のようになるでしょう。
CREATE TABLE seminar (
seminar_id INT PRIMARY KEY,
thedate DATE,
starttime TIME,
title TEXT,
place TEXT,
memo TEXT
);
CREATE TABLE attendant (
attendant_id INT PRIMARY KEY,
seminar_id INT,
cacel INT,
name VARCHAR(32),
mail VARCHAR(64),
company VARCHAR(64),
section VARCHAR(64),
title VARCHAR(64),
zipcode VARCHAR(7),
address TEXT,
tel VARCHAR(20)
);しかしこうなると、複数のセミナーが存在するということを基にしたページ設計が必要です。スタッフが参照するページは、セミナー自体の選択をして、その参加者一覧が表示されるような、マスター/ディテール形式のユーザーインターフェースが一般的でしょう。そして、参加申し込みで日付が入力される方法を考えなければなりませんが、これは実はビジネスモデルによって大きく変わると思われます。いずれにしても、「セミナーそのものを管理しなければならない」ということを考えれば、ユーザーインターフェースの設計は図9-4-2のようになります。スタッフが見るページがひとつ増えていて、そのセミナーの一覧はseminarテーブルを基にしたコンテキスト定義より作成が可能です。
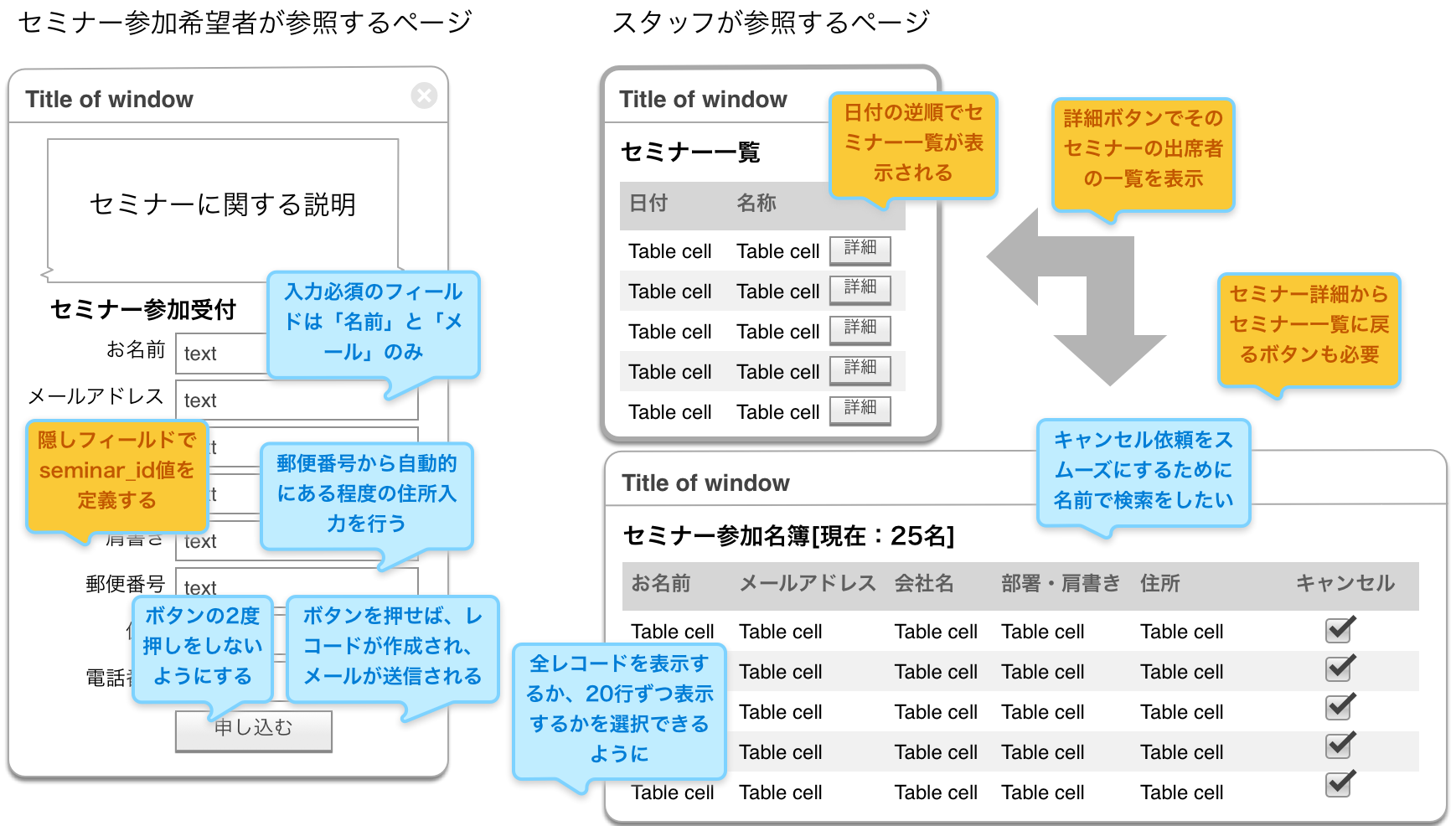
これでいいでしょうか? こうして実際に動きそうな画面を見ると、いろいろな要求が欠けていたことが分かります。それらを列挙すると次の通りですが、これらで全てであるかどうかは分かりません。さらに要求が出てくるかもしれません。いずれにしても、これらの要求のひとつひとつについて、要求として記述し、それを元に開発プロセスを回します。ユーザーインターフェースの変更だけで終わるものもありますし、ユーザーインターフェースの追加や新たなコンテキストの識別が発生するでしょう。
- 参加受付のページに名前の読みを入れるフィールドがない。
- 入力を間違えた時の対処はどうする? メールを見て参加者がメールや電話してくるとしたら、スタッフが個人個人の情報を変更できるようにしておく必要がある。その方法が具体的には記載されていない。
- 新しくセミナーを作った時、日付やタイトルなどを入力するレイアウトができていない。
- キャンセルをクリックしたら、即座に消えるという動きをしたい。
- キャンセルを復活するのはどうすればいいか? これも、おそらくメールや電話で依頼が来ると思われるので、スタッフがキャンセルの復活が可能なユーザーインターフェースがさらに必要である。
- 参加受付は認証なし、しかしながら、スタッフ側のページは、たとえリンクされていないページだとは言え、そのまま公開するのは危ないので、認証ができるようにしたい。そうなると、認証ユーザーの登録ページも欲しい。
開発作業のプロセスとしては、要求定義、ユーザーインターフェースとページファイル、コンテキストの識別、定義ファイルでのコンテキスト定義、スキーマ定義といった流れになりますが、立て板に水を流すかのような一方向の流れで終わるということはありません。ある要件を実現するうちに気付かなかった、つまり明言できなかった要求がどこかの段階で増加し、その結果ユーザーインターフェースを追加したり変更したりすることが必要で、結果的にコンテキストやスキーマ定義への変更も必要です。このように、いくつかの作業をぐるぐると繰り返しながらなるべく完成に近づける作業を「イテレーション」と呼びます。
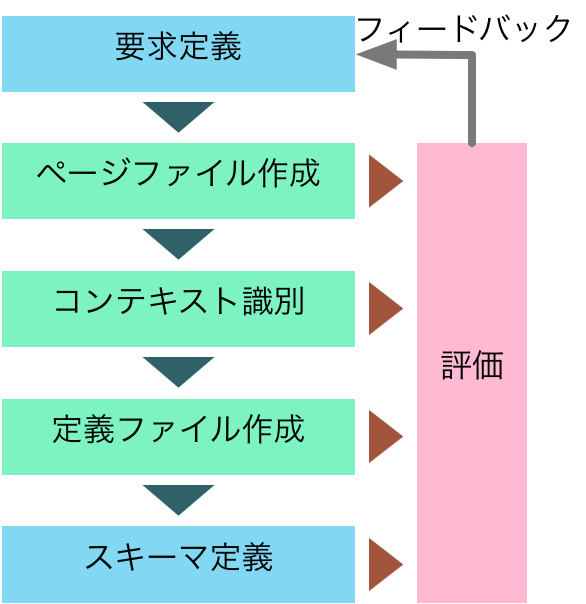
いくつかのプロセスが一方向に進められるのは、一般にはひとつのプロセスでの作成結果を変更することに多大なコストがかかる場合に取られる方法です。そのため、時間やコストをかけて、ひとつのプロセスの成果物を出し、その完成度が高いものとして、次のプロセスに引き継がれてプロセスが進行するということになります。しかしながら、ここで紹介したようなイテレーションは、ひとつひとつのプロセスの作業はそれほど重くなく、修正も容易です。むしろひとつひとつのプロセスをじっくりやるよりも、手のつけられるところから進められるという意味ではより気軽な手法と言えるでしょう。また、結果的にINTER-Mediatorを使ったアプリケーションの骨格部分を構築している作業に一部は対応しており、上記の作業は設計でもありますが、構築でもあるのです。
アジャイル開発の原則をシンプルな言葉でまとめた『アジャイルソフトウェア開発宣言』の記述(この段落では「」で記載)と、ここまでに紹介したプロセスの対比をしてみましょう。開発プロセスを一人で行う方もいらしゃるかもしれませんが、職場で作業をするとしたら何人かのスタッフ同士で検討をするでしょう。その結果「個人との対話」が発生します。そして、INTER-Mediatorで作成した場合は、データベース、定義ファイル、ページファイルが揃えば何かしら「動くソフトウェア」ができ上がります。そして、作り込む部分が少ないうちは「変化への対応」も容易です。他に「顧客との協調」という記述がありますが、ここで紹介する手法を顧客あるいは開発者と顧客が取り組むとしたら、まさにそれは協調以外の何物でもありません。このように、INTER-Mediatorを利用した開発プロセスは、アジャイル開発であると言えます。
ちなみに、こうした「まずはHTMLファイルを作って考える」という手法は、アジャイル開発のひとつのプラクティスである「モックアップ駆動開発(mockup driven development)」として提唱されています(英語で検索するとさまざまな論文が出てきますが日本語だと何も出ません)。HTMLだけだと、手続き的なプログラミングを習得していないような非プログラマーの利用者も作成できますし、さまざまなツールがあってコードを書かないで作り込むこともできるというメリットが大きいでしょう。加えて作成にそれほどの時間がかからないことや修正が容易ということもあり、開発の早い段階で最終的なイメージを見せることができます。その後にデータがそのページに乗るような流れでスムーズに発展させられます。しかしながら、INTER-Mediatorは単なるモックアップ駆動開発ではなく、モックアップが「動作する」ところにひとつの進歩があります。
一方で、「HTMLを作って開発するのは良くない方法である」という論調もあります。このような論調の根底にある原因は、「HTMLにはすべての情報が込められていない」ということに尽きると思います。確かに、単にHTMLをいきなり作るだけでは、実際の表示内容はどうなるのか、きちんと提示できないということもあります。しかしながら、このセクションで説明している方法は、最初に要求を記述して、要求を定義し、何をやりたいのかということが比較的細かなレベルまでも記述されているということがあります。もちろん、読みやすさや記述の的確さなどの要求定義のクオリティの問題もありますが、最初に何ができるようになっているのかという議論を経た上でHTMLでのページのモックアップ(システムの見本)を見ることは、それらの議論がより具体化された結果を見ていることであり、開発フェーズとしては無駄なものではなく、さらに進めた結果を見ていると言えるでしょう。
必要な実装を進める
短期間で設計・テスト・検証・改善というイテレーション作業を繰り返すうちに、次第に定義ファイルやページファイルには詳細な記述が増えることになるでしょう。このとき、要求定義として記述したやりたいことを実際に開発結果に組み込むとき、その処理をINTER-Mediatorが用意しているかどうかで対処が変わります。例えば、記録しているデータを表示するだけならば、単にページファイルにdata-im属性を記述するだけです。データを表示するとき、ちょっと変更して表示したい場合、それが書式設定のような単一のフィールドに関連するものや、同一レコードから求められるものであれば、calculationキーをコンテキストに記述して計算プロパティを定義して、そのプロパティ名をdata-im属性に記述します。一方、ボタンを押したらフィールドの値が更新されるようにしたい場合は、INTER-Mediatorはそのような機能を持ちませんから、通常はJavaScriptでプログラムを書くことになるでしょう。
ここまでで示している「セミナーの出席者リストを作る」という作例で考えていきましょう。まず、参加申し込みを行うページでは、単に申し込みの受付を行うので、これはポストオンリーモードでのページ作成で実現できそうです。ポスト時にバリデーションを行うため、コンテキスト定義にはvalidationの設定を行います。また、このままではデータを誰もが読めてしまいますので、データベース処理のうちレコード作成以外は存在しないグループdummyでしかできないように設定して、事実上誰もレコード作成以外のデータベース処理はできず、レコード作成のみ誰でもができるようにしておきます。また、「申し込む」ボタンをクリックしたあと、ボタンの位置に「お申し込み受付ました。確認のメールをごらんください。」と表示して、再度ボタンが押されないようにしつつ、受け付けられたことを利用者にフィードバックするとします。ページファイルの主要部分をリスト9-4-4、コンテキスト定義をリスト9-4-5に示します。ページファイルにあるseminar_idフィールド向けの隠しフィールドにある「20」という値は、何らかの方法で、参加受付しているセミナーのテーブルの主キー値を得て手作業で記述したものとします。
<table>
<tbody data-im-control="post">
<tr><th>名前</th><td><input type="text" data-im="attendingpost@name"/></td>
<tr><th>メールアドレス</th><td><input type="text" data-im="attendingpost@mail"/></td>
:
<tr><th></th><td>
<input type="hidden" data-im="attendingpost@seminar_id" value="20"/>
<button data-im-control="post">申し込む</button>
</td>
</table>name: attendingpost
view: attendant
table: attendant
id: attendant_id
validation:
[field: name, rule: length(value)>0, message: 入力必須です, notify: inline]
[field: mail, rule: length(value)>0, message: 入力必須です, notify: inline]
authentication:
[read: [group: [dummy]]],
[update: [group: [dummy]]],
[delete: [group: [dummy]]]
post-dismiss-message: お申し込み受付ました。確認のメールをごらんください。同様に、スタッフ側のページも設計を進めるとさまざまな要素が必要になります。ここでは数多くなるので、ポイントだけを示します。まず、セミナー一覧と出席者一覧については、マスターディテール形式の仕組みを利用することにします。ただし、ディテール側はいきなりattendantテーブルを表示するのではなく、seminarテーブルを1レコード配置し、その内部にattendantテーブルのコンテキストを一覧として展開します。これは、参加者リストにもセミナー日やタイトルなどのseminarテーブルの値を表示したいというところから来ています。seminarテーブルは一覧用のseminarlistとディテール領域用のseminardetailの2つのコンテキストとして実現します。セミナー一覧は日付の逆順とするので、sortキーの定義がコンテキスト定義には必要です。出席者一覧では、名前の読みの順でsortキーの定義を記述します。また、出席者一覧では、キャンセルしていない人の一覧を出すためのqueryキーの定義を行います。なお、セミナー一覧上でフィールドの値を変更できるようにINPUTタグにしているので、これで全てのフィールドではありませんが、主要なフィールドの入力はできます。attendantテーブルの方は、このページファイルでは修正はできないので、別途作成することになると思われます。ページファイルの主要部分をリスト9-4-6、コンテキスト定義をリスト9-4-7に示します。なお、定義ファイルの2つ目の引数(オプション指定)において、全てのデータベースアクセスを認証が必要であるように設定するようにします。
<table>
<thead>....</thead>
<tbody>
<tr>
<td></td>
<td><input type="text" data-im="seminarlist@thedate"></td>
<td><input type="text" data-im="seminarlist@title"></td>
</tr>
</table>
<div data-im-control="enclosure">
<div data-im-control="repeater">
<p>ID:<span data-im="seminardetail@seminar_id"><span>
セミナー実施日:<span data-im="seminardetail@thedate"><span></p>
<div id="IM_NAVIGATOR"></div>
<table>
<thead>....</thead>
<tbody>
<tr>
<td></td>
<td data-im="attendantlist@name"></td>
<td data-im="attendantlist@mail"></td>
:
<td><input type="checkbox" data-im="attendantlist@cancel" value="1"/></td>
</tr>
</table>
</div>
</div>name: seminarlist
view: seminar
table: seminar
id: seminar_id
sort: [field: thedate, direction: DESC]
repeat-control: confirm-insert-top, confirm-delete
navi-control: master-hide
name: seminardetail
view: seminar
table: dummy
id: seminar_id
records: 1
navi-control: detail
name: seminarlist
view: attendant
table: attendant
id: attendant_id
paging: true
sort: [field: yomi, direction: ASC]
query: [field: cancel, operator: !=, value: 1]
relation: [foreign-key: seminar_id, join-field: seminar_id, operator: =]もちろん、これで完成ではありません。まだまだ、積み残した要求があります。実際に業務ができるところまで、要求を実現しなければならないのは言うまでもありませんが、ここでは作業の流れを示したいので、開発作業結果の紹介はここまでとします。
要求を考えるときに「何をする」のかがしっかり抽出されていれば、あとはその機能があるかどうかの判断で、あるのならページファイルや定義ファイルに記述を加えます。ないのであればJavaScriptやPHPでの拡張ポイントを検討して組み込みを行います。しかしながら、実際に組み込みを行うと、要求で考えた以上のことをやらなければならないことが多々あります。それらは頑張って新しい視点で実装をするしかないでしょう。例えば、単にデータやページ上の表示を考えれば、一覧された結果の中のあるフィールド値の合計は簡単に求められそうに見えます。もちろん、単なる合計は、計算プロパティで求めることも可能です。しかしながら、条件付きの集計をしたい場合はどうでしょうか? 別のフィールドの値が一定以上であれば、合計対象に含めても、そうでないなら合計に入れないという仕組みの実装はどうすればいいでしょうか? これについては、いくつかの答えがあります。SQLデータベースなら、そうした計算処理を組み込んだビューを作っておくことで対処できます。また、エンクロージャーに全てのリピーターが合成された後に呼び出されるメソッドをコンテキスト定義で指定し、JavaScriptのプログラムにおいて、コンテキストの値を参照しながら、自分で繰り返し処理を記述して条件付きの合計計算をするという方法もあります。後者の手法は、ページ合成処理に割り込む処理の記述、コンテキストの取り出し、JavaScriptによる計算処理といった知識が必要になるでしょう。手続き的なプログラミングが必要な拡張点に限っては専門家に作ってもらうという手もあります。
コンピューターでのシステム開発に限らないのかもしれませんが、中間に存在するさまざまな議論をすっ飛ばして最終結果に目が向きがちです。例えば、「○○というフレームワークを使うと良いらしい」という結論ありきで、なぜそのフレームワークが良いのかということを考えていない関係者が散見されます。問いただして出てくる答えも「ブログで偉い人が言っていた」くらいの理由しかありません。どんなフレームワークでも、適用範囲とその利用プロセスが妥当かどうかという判断が先にあるはずです。ここで紹介したプロセスは最初に説明した通り、エンジニアでない人でも頑張ればできる範囲を想定したものです。INTER-Mediatorは、エンジニアでもない人が全てできるとは主張しませんが、エンジニアでない人でも開発作業やメンテナンス作業の一定部分を賄えるというシナリオを描けるという点を理解していただきたいと考えます。
フレームワークを使うとしたら、それをどのようにマスターすればいいのかということに注目が集まるのは世の常です。しかしながら、本当に重要なのは、INTER-Mediatorにタッチするまでの分析にあり、その分析を効率よく進める開発プロセスにあります。分析で俎上に上がったことはなんとかなるものです。しかし、分析で一切気付かないでいたことがシステムに組み込まれるのは奇跡に近い話です。そのため、初期の段階からきちんと記述を残すことを意図した要求のピックアップを重視すべきだと考えます。そして、INTER-Mediatorで利用できる機能で要求が実現できるかどうかを検討し、直接実現できるものはともかく組み込みましょう。場合によっては何段階かの作業が必要なものもあります。しかしながら、手続き的なプログラミングが必要な要求もあるということです。
UMLによる設計記述は、批判も多々あるものの共通のルールでダイアグラムを作成できるメリットは大きいでしょう。一方、「クラス図」「オブジェクト図」とあるように、原則としてオブジェクト指向の考え方が根底にあります。もちろん、ユースケース図やシーケンス図のような、オブジェクト指向という視点ではないものもありますが、UMLの成立過程を見ても、オブジェクト指向開発のひとつの達成点であることは間違いないでしょう。そのため、UMLを使いこなすにはオブジェクト指向プログラミングを基礎として習得している必要があります。しかしながら、INTER-Mediatorのように最終的にクラスを作ることを意図しないようなフレームワークでは、オブジェクト指向的にまとめ上げる必要性はあまりありません。特に最近のWebクライアント系フレームワークは、オブジェクト指向色が少ないこともあり、開発プロセスとしてどのような手法を取り入れていくのかについてのアイデアはこれから出てくるといったところでしょうか。この書籍の最後のセクションを書きながら、筆者はブログ上に記事を書き溜める形式で、現在のクライアントとサーバーを巻き込んだWebシステムのモデリングをどのようにすればいいかを考え始めています。クラスやオブジェクトというより、「やりたいこと」「させたいこと」という要求レベルでの単位をベースに、フレームワークの機能で分解して記述したニーズをまとめ、フレームワーク外の機能を抽出してオブジェクト指向的に手続き的なプログラムを作成するといった流れを想定しています。こちらは時間がかかるかもしれませんが、まとまった結果が出れば、INTER-Mediatorコミュニティには必ず還元できるものが得られると信じています。
データベーススキーマを用意する
データベースを利用したアプリケーションでは、データベース設計であるスキーマが肝であることは当然です。データベースの設計がすべての基礎になることはもちろんです。データベース上で想定していないことは、どんなに頑張っても実現できない可能性が高く、「想定されるあらゆる状態を記録できる」ようなスキーマを設計するのが基本であるとも言えます。そのため、SQLの定義言語は実にさまざまな機能があります。
INTER-Mediatorでアプリケーションを作成する場合、どこまでを実際にデータベースのスキーマとして込めるのかということがあります。機能的には、テーブル定義、フィールド定義、フィールドの型くらいの定義で構いません。ただし、実用的には、主キー設定とユニークなインデックス、検索フィールドに対するインデックスは必要になります。その他の外部キー、初期値あたりは必須ではありませんが、設計時には意識はすることになると思われます。外部キー自体の設定は、relationキーでコンテキストに定義することになりますし、初期値はコンテキストやあるいはJavaScriptで指定するなどさまざまな方法があります。制約をどこで記述したいのかによって記述場所をよく検討しましょう。一般に外部キー制約は、リンクされていないレコードの作成を阻止するなどの目的を持って行われます。
SQLデータベースを利用する場合は、ビューを積極的に活用しましょう。データを取り込んでから処理をプログラムで書くよりも、SQLの段階で集計をしてしまう方が、一般には処理時間が短くなります。また、リレーションシップを適用した後の結果をビューとして取り込む方が、コンテキストの階層化により複数回のサーバーアクセスを行うよりも明らかにスピードアップの効果が出ます。あまりに節操なくビューを作ると何が何だか分からなくなりますので、用途を整理しながらビューを作って、それを元にコンテキストを組み立てるように進めれば良いでしょう。
データベースを作成してユーザーを作り、権限を与えてテーブルを作成するという一連のスキーマ定義コマンドは、INTER-Mediatorフォルダーのdist-docsにある各データベースごとのサンプルのスキーマファイルが参考になると思われます。SQLデータベースでの認証関連のテーブルについては、このファイルから必要な箇所をコピー&ペーストすればいいでしょう。また、Samples/templates/least_schema_mysql.sqlというファイルは認証関連のテーブル定義とひとつのサンプルのテーブル定義なので、このファイルを基にして作成してもいいでしょう。
このセクションのまとめ
一般的なWebアプリケーションフレームワークでは、旧来からの手続き的プログラミングを主体とした開発プロセスを踏襲あるいは改良した手法で語られることが多いでしょう。一方、INTER-Mediatorは、利用開始初期段階では手続き的プログラミングのコードを「書かない」ことを主眼としており、その点では他のフレームワークと大きく異なります。書かないのは存在しないのではなく、フレームワークにいつも最初に書くようなプログラムが内包されていて、アプリケーションを作る人はそのフレームワークに込められた仕組みを再利用しているのです。Webシステムを一般化すれば、ページとデータベースの連携が根底にあり、その仕組みを基礎として自分が必要な仕組みをさまざまな手法で組み込むという考え方でINTER-Mediatorは利用できます。
9-5Webアプリケーションの構築作業
INTER-Mediatorを使ったWebアプリケーションを実際に作る時のディレクトリ構成や、あるいはフレームワーク自体のセットアップなどを説明します。
INTER-Mediatorのセットアップ
INTER-Mediatorは、Ver.6以降、composerを稼働させることによるセットアップの作業が必要になりました。composerはもちろん、PHPのライブラリをダウンロードしてセットアップする仕組みですが、INTER-Mediatorのセットアップ用ファイルでは、さらにNode.jsもインストールして、npmによるJavaScriptのライブラリのセットアップも行います。原則として、composerに関連するコマンドを入れればあとは自動的に全て行いますが、この辺りの動作について知っておくことで、トラブルシューティング等に強くなれるかと思われますので、手順だけでなく、仕組みについても折に触れて説明します。
まず、INTER-Mediatorの稼働方法とセットアップについては、以下の3通りの動作を想定しています。
- INTER-Mediatorをダウンロードしてその状態で稼働させる。
- INTER-Mediatorをアプリケーションの一部としてインストールし稼働させる。
- INTER-Mediatorをcomposer管理のライブラリとして稼働させる。
最初のセットアップは、INTER-Mediatorそのものをダウンロードして、その中のサンプルなどをとりあえず動かしたいというような場合に相当すると思われます。実用的なアプリケーションは2つ目や3つ目の手法を取ることが一般的と考えます。それぞれの方法を説明します。
INTER-Mediatorをダウンロードしてその状態で稼働
この方法では、レポジトリをgit cloneコマンドで取り出したり、あるいはリリースファイルとして配布されているファイルをダウンロードして稼働させる場合が多いでしょう。原則として、PHPが稼働し、何らかのデータベースが稼働する環境を用意した上で、INTER-Mediatorをダウンロードします。そして、ダウンロードして展開したフォルダを「INTER-Mediator」フォルダとすれば、このフォルダをカレントディレクトリとして、以下のようにコマンドを入力します。
composer updateこの方法では、単にcomposerコマンドを稼働するだけです。サブコマンドはinstallじゃないのかという指摘もあるかもしれませんが、INTER-Mediatorのディストリビューションにはロックファイルもあるので、updateで作業する方が早いと思われます。もっともinstallで作業しても構いません。なお、PHPのバージョンによっては「composer install」とした方が良い場合も過去にはあったのですが、いずれにしても、「composerを動かす」だけです。
これにより、必要なPHPのライブラリが、まずは、INTER-Mediator/vendorフォルダ以下にインストールされます。その作業の中で、Node.jsもインストールをします。Node.jsはバージョンの違いによって色々問題が発生する場合があり、原則としてバージョンを指定しています。その指定は、INTER-Mediatorのレポジトリのルートにあるcomposer.jsonファイルに記載があります。執筆時点では、Ver.18.16.0に固定してあります。
PHPのライブラリのインストール後、自動的に背後でnpmを実行します。そして、INTER-Mediator/node_modulesフォルダに、ライブラリが入ります。INTER-Mediator自体もすでにある程度はライブラリ化しているので、実は、それらがセットアップされていないとINTER-Mediatorは稼働しませんが、いずれにしても、作業としてはcomposer updateをするだけですが、自動的に背後でnpmによるセットアップも動いている点は知っておく必要があります。
この後、INTER-Mediator自体をアップデートしたい場合は、レポジトリのルートで「git pull」などを行います。その後、「composer update」を行い、PHPとJavaScriptのライブラリを更新します。
この状態のINTER-Mediatorを稼働する一番手軽な方法は、INTER-Mediatorディレクトリをカレントにして「php -S localhost:9000」などのPHPのサーバモードを利用することです。
INTER-Mediatorをアプリケーションの一部としてインストールし稼働
INTER-Mediatorのアプリケーションを作成する場合、アプリケーションのルートに「lib」ディレクトリ、その中に「src」ディレクトリがあるものと想定しています。そして、srcディレクトリをカレントにして、git cloneで、INTER-Mediatorのレポジトリのクローンを作ります。しかしながら、srcフォルダの中のINTER-Mediatorは稼働用ではありません。逆に、何か変更が必要な場合はこのsrcにあるINTER-Mediatorの修正を行います。
そして、まず、composer updateコマンドを稼働して、srcディレクトリのINTER-Mediatorをセットアップします。その後に、lib/src/INTER-Mediatorをカレントにして、以下のように「buildup.sh」スクリプトを稼働させるのですが、このスクリプトは「dist-docs」フォルダにあるので、相対パスで指定をしてスクリプトを稼働します。すると、図のように表示されて入力待ちになります。ここでは、1から4のいずれかの数値を入力してリターンキーを押します。通常は、(2)〜(4)のいずれかを選択してセットアップすると思われますが、いずれを選んでも、INTER-MediatorのJavaScriptコードが最小化されてひとつのファイルにまとめられるので、クライアント側からのダウンロードが早くなることが期待できます。
% composer update
% dist-docs/buildup.sh
=================================================
Start to build the INTER-Mediator Ver.11
-------------------------------------------------
Original: /Users/msyk/Code/INTER-Mediator
Build to: /Users/msyk/Code/im_build/INTER-Mediator
Path of minifyer (installed by composer): /Users/msyk/Code/INTER-Mediator/vendor/matthiasmullie/minify
-------------------------------------------------
Choose the build result from these:
(1) Complete (everything contains)
(2) Core only (the least set to work web applications)
(3) Core only, and move it to 3-up directory (the ancestor of original INTER-Mediator)
(4) Core only without Socket-IO, and move it to 3-up directory
Type 1, 2, 3 or 4, and then type return---->(2)だと、サンプルやテストコードなどがないものを、INTER-Mediatorと同じディレクトリに「im_build」ディレクトリを作り、その中に稼働用のINTER-Mediatorフォルダとレシート(作業報告)となるテキストを用意します。(3)は、「3-up directory」と記述がありますが、これは、lib/src/INTER-Mediatorをカレントにして作業した場合、libの直下に稼働用のINTER-Mediatorフォルダを作ることを意味しています。つまり、src直下にクローンし、スクリプトを動かしてそこからlib直下に稼働用のINTER-Mediatorを作ります。もちろん、フォルダ移動等の手間を省くための方策です。lib直下にすでにINTER-Mediatorディレクトリがある場合、元からあるINTER-Mediatorディレクトリは一旦削除して、新たに生成し直します。(4)は(3)に加えて最小化したJavaScriptコードを作るときにその中にSocketIOを含めないようにしてなるべくコードサイズを小さくする選択肢です。なお、通常は最小化したコードは450KBほどありますが、SocketIOを除くと380KBほどになります(Ver.12の途中の実測値)。
稼働するアプリケーションでは、lib/INTER-Mediator/INTER-Mediator.phpをrequireステートメントで読み込むことで、INTER-Mediatorの利用が可能になります。実際のファイル構成についてはこの後の『サイトのディレクトリ構成』で説明を行います。
なお、buildup.shスクリプトを動かすことで、composer updateやnpm updateが自動的に行われ、lib/INTER-Mediator直下にvendorとnode_modulesディレクトリが作成されてファイルがたくさんそこにコピーされ、さらには最小化されたINTER-Mediatorが用意されます。
この方法でインストールする場合は、params.phpファイルはlib直下に配置することができます。つまり、INTER-Mediatorディレクトリの外部に配置できるので、その後のINTER-Mediatorの入れ替えはより気軽にできるでしょう。もちろん、INTER-Mediator内にあるparams.phpをコピーしてlib直下に配置し、その後に修正をします。
buildup.shスクリプトを動かせば、その時のカレントディレクトリのINTER-Mediatorディレクトリと同じ場所にim_buildディレクトリを作ります。(3)を選択すると、そのディレクトリにはINTER-Mediatorフォルダは生成しませんが、レシートのテキストファイルは作成します。
INTER-Mediatorをcomposer管理のライブラリとして稼働
この方法は、INTER-Mediator自体をPHPのライブラリとして扱います。したがって、INTER-Mediator自体の特別なインストール作業は基本的には一切ありませんが、一定のルールに従ってアプリケーションを構築する必要があります。これについては、この後の『INTER-Mediatorによるアプリケーション』で紹介します。
サイトのディレクトリ構成
Webサーバの公開ディレクトリ、あるいはその中のディレクトリとして、アプリケーションは展開すると思われます。ここでは、『INTER-Mediatorのセットアップ』の『INTER-Mediatorをアプリケーションの一部としてインストールし稼働』で説明した方法で、INTER-Mediatorを稼働されるとします。
それぞれのページが独立したページファイルと定義ファイルから構成されるのであれば、それらは同一のファイル名にしておくのが一番わかりやすい整理方法でしょう。ごく小規模なサイトの場合、ひとつの定義ファイルに対してページファイルが複数存在することもあるでしょう。そのような状態でも問題はありませんが、定義ファイル名であること識別しやすい名前(例えば「def_file.php」など)にしておくと管理しやすくなります。
ページファイルが数えられる程度なら、ページファイルと定義ファイルを同一のディレクトリに並べても、それなりに管理はできるものです。しかしながら、10種類以上のページファイルがあるような場合には例えば用途ごとにディレクトリに分類した方がいいでしょう。ひとつのディレクトリ内に複数のページファイルや定義ファイルがあってもいいのですが、これも数が増えてくれば、複数のディレクトリにさらに分類します。さらに、JavaScriptのファイルや、PHPの拡張機能として利用するアドバイス定義ファイルについても、ページファイルや定義ファイルと同じディレクトリに入れておくのが混乱のない方法です。なお、INTER-Mediatorやそのほかのライブラリは、ルートにlibなどのディレクトリを作っておいて、そこにまとめて入れておきます。params.phpはルートではなくlibディレクトリの中に作成します。libにはそのほかのライブラリなどを入れてもいいでしょう。そして、lib/src/INTER-Mediatorから、dist-docs/buildup.shスクリプトにより、lib/INTER-Mediatorを生成して利用します。
FuncA
└ index.html(ページファイル)
└ Page1.php(定義ファイル)
└ Page1.js(ページ内の処理を行うJavaScript)
└ Page1.js(JavaScriptファイル)
└ Extending.php(PHPファイル:アドバイス定義クラスのファイルなど)
└ Page2.html(ページファイル)
└ Page2.js(ページ内の処理を行うJavaScript)
└ Page2.php(定義ファイル)
FuncB
└ index.html(ページファイル)
└ Page3.php(定義ファイル)
└ Page4.html(ページファイル)
└ Page4.php(定義ファイル)
start_page.html(ページファイル)
start_page.yaml(定義ファイル)
lib
└ INTER-Mediator(src以下のINTER-Mediatorからbuildup.shスクリプトで生成したもの)
└ INTER-Mediator.php
└ ...
└ params.php(設定ファイル)
└ styles.css(CSS定義ファイル)
└ src
└ INTER-Mediator(レポジトリからクローンしたもの)ページファイルのヘッダー部には、同じディレクトリにある定義ファイルを参照すればいいので、例えばFuncA/index.htmlでは図9-5-1のようにSCRIPTタグでsrc属性に単にファイルを記述すればよいでしょう。定義ファイルでは、図9-5-2のようにINTER-MediatorのルートにあるINTER-Mediator.phpファイルを相対パスで指定して、INTER-Mediator本体を読み込み、IM_Entry関数を利用します。
<head>
<link rel="stylesheet" href="../lib/styles.css">
<script type="text/javascript" src="Page1.php"></script>
<script type="text/javascript" src="Page1.js"></script><?php
require_once("../lib/INTER-Mediator/INTER-Mediator.php");
IM_Entry([...], [...], [...], 2);INTER-Mediatorによるアプリケーション
INTER-Mediatorは、composerでインストールされるライブラリとしての動作も可能となっています。ただし、PHPだけでなく、JavaScriptの要素もあるので、単にcomposer.jsonに登録すれば良いということではありません。いくつかの要件を満たさないといけないのですが、その要件を満たすようなアプリケーションのレポジトリを作るためのテンプレートが用意されています。そのテンプレートはGitHubで、https://github.com/INTER-Mediator/IMApp-templateにおいて公開されています。まずは、それを利用したアプリケーション開発方法を説明し、そのテンプレートに備わった機能を説明しましょう。
アプリケーションを作成する手順を以下に示しますが、この順番通りということではなく、スキーマやページのコードは作っては修正等を行うなど、もちろん手順はある程度は行き来はすると思われます。まずは手元の開発用マシンで、PHPが稼働しており、加えて、MySQLないしはPostgreSQLが稼働しているという状況で、以下のように作業を行います。
- テンプレートのレポジトリ「IMApp-template」を元にアプリケーションのレポジトリを作る。ページ右上にある「Use this template」から「Create a new repository」を選択し、あとは自分のアプリケーション用のレポジトリの名前を指定するなどしてレポジトリを作成する。
- そのレポジトリを、自身の開発用マシン等にクローンする。
- lib/MySQL_Schema、lib/PosrgreSQL_Schemaにそれぞれいくつかファイルがあるので、そのファイルを修正して、アプリケーションに必要なデータベース設定を用意します。実際の適用は、composerコマンドで実施されます。
- lib/params.phpが実際にアプリケーションで利用されるparams.phpファイルです。そこにデータベース接続設定など必要な設定を行います。
- lib/doafterinstall.sh、lib/doafterupdate.shファイルを開き、最初の変数でデータベースの種類とデータベース名を指定します。
- レポジトリのルートで、「composer install」を入れます。INTER-Mediatorを含むさまざまなPHPおよびJavaScriptのライブラリがインストールされます。
- レポジトリ内にページファイルや定義ファイルなどのアプリケーション本体を作成する。
- 適当なところでレポジトリにコミットし、pushしてGitHubのレポジトリに更新結果を反映する。
完成したアプリケーションを稼働サーバにセットアップするときは、レポジトリをクローンし、「compser install」を行うだけで良いでしょう。composer installコマンドにより、lib/doafterinstall.shコマンドが実行されてデータベースへのスキーマ適用まで自動的に終わらせるようにしています。
テンプレートにはINTER-Mediatorは存在しませんが、composerにより、vendor/inter-mediator以下に、INTER-Mediator本体がインストールされます。PHPのライブラリは、INTER-Mediator自体が統合可能な状態で作ってあるのでもちろん稼働しますが、JavaScriptのライブラリについては、INTER-Mediatorの内部でnode_modulesディレクトリを用意して、そこにインストールするようになっています。このことを実現するために、ルートにあるcomposer.jsonの中でscripts/post-install-cmdおよびscripts/post-update-cmdの定義で、INTER-Mediatorのルートに移動してnpm install/updateを実施し、加えてINTER-Mediator内部のdist-docs/generateminifyjshere.shスクリプトを稼働して、JavaScriptの最小化コードを作成してあります。したがって、INTER-MediatorによってインストールされたJavaScriptのライブラリは、パスを正しく指定すればアプリケーションで利用できますが、アプリケーションがnpmによるインストールが必要なJavaScriptライブラリを使う場合は、アプリケーションで別途package.jsonファイルを用意して、npm installコマンドを手で入れる必要はあります。あるいはnpm installコマンドを、lib/doafterinstall.shあるいはlib/doafterupdate.shに追加してください。
テンプレートにはサンプルとして簡単な住所録がsample_pageディレクトリにありますが、そこにある定義ファイルのindex_contexts.phpの冒頭では、次のようなrequire_onceステートメントがあって、これにより、composerでインストールしたINTER-Mediatorを使えるようになります。アプリケーションでのPHP形式の定義ファイルについては以下のように、vendor以下のINTER-Mediatorを参照するようにします。また、YAML形式の場合でページファイルと定義ファイルが同一のディレクトリにあって同じファイル名の場合には、INTER-Mediatorのフレークワークのルートにあるindex.phpを参照します。
// PHPの定義ファイルでINTER-Mediatorを取り込む箇所の記述例
require_once '../vendor/inter-mediator/inter-mediator/INTER-Mediator.php';
// YAMLの定義ファイルをページファイルから参照する場合のコード例
// ページファイル名と定義ファイル名が同一で同じディレクトリに存在する場合
<script src="/vendor/inter-mediator/inter-mediator/index.php"></script>
// INTER-Mediatorの中でインストールしたJavaScriptコードをページファイルで利用する
// 以下はJQuery FileUploadを利用する場合の例
<script src="../vendor/inter-mediator/inter-mediator/node_modules/inter-mediator-plugin-jqueryfileupload/index.js"></script>params.phpについても、composerでインストールした場合は、INTER-Mediatorのルートから2つ上のディレクトリにあるlib以下に存在することを仮定しています。つまり、アプリケーションのルートにvendorディレクトリが作られる前提で、アプリケーションのルートにあるlibの直下にparams.phpを用意しておけば、そのparams.phpファイルが優先的に使われます。
テンプレートでのデータベーススキーマ運用
テンプレートのlib/MySQL_Schemaやlib/PosrgreSQL_Schemaには、ディレクトリ名に相当するデータベースのスキーマ定義ファイルが掲載されています。それぞれのディレクトリには、表9-5-1に示すような4つのファイルが用意されています。なお、適用される順序は、表の順序に一致しています。
| ファイル名 | Install | Update | 内容 |
|---|---|---|---|
| schema_basic.sql | 適用 | テーブルの定義。INTER-Mediatorの動作に必要なテーブルも定義されている | |
| schema_update.sql | 適用 | update時に実行するSQL | |
| schema_views.sql | 適用 | 適用 | ビューの定義 |
| schema_initial_data.sql | 適用 | 初期データ。ログインユーザとサンプルデータがある |
composer installをしたときにはテーブル、ビューの定義と初期データの書き込みを行います。composer updateをしたときには、ビューの定義とupdate時専用のファイルを実行します。テーブルとビューの定義や初期データはSQLそのものです。なお、テーブル定義はupdateでは利用されないのですが、ビューの定義は利用します。そのため、CREATE VIEW aview...ではなく、CREATE OR REPLACE VIEW aview...で定義をビュー定義をしてください。そうすると、updateのときにスムーズにビューの更新ができます。
update時の運用について説明をしましょう。例えば、フィールドを追加したという場合、もちろんテーブル定義を書き換えるのが基本ですが、CREATE TABLEをそのまま適用すると、テーブルが一度作成し直されてしまいます。そこで、schema_udate.sqlに「ALTER TABLE ADD COLUMN afield TEXT;」などと記述すれば、composer updateでスキーマの更新もできてしまいます。ただし、2度同じコマンドを実行するとエラーになるので、composer update実行後にschema_update.sqlの中身を消すなどのメンテナンス作業は必要です。ビューについては、composer udateの時に常に適用するようにしているので、ビューの変更はschema_views.sqlを書き直すだけで大丈夫です。
こうしたスキーマの自動適用は、lib/doafterinstall.sh、lib/doafterupdate.shに記載があります。もし、問題があれば、これらのスクリプトを書き直しましょう。例えば、macOSではHomebrewを使い、Linuxではsudo mysqlによってroot利用できることを仮定しています。データベースやサーバのバージョンによっては何かしらの対処は必要になる可能性がありますので、エラーや適用されていないなどの問題があれば、これらのスクリプトをチェックしてください。
初期データの中には、管理者と一般ユーザを想定したadminとuserという2つのアカウントが定義されています。また、ファイルを見れば明白なように、これらで利用するパスワードは「Quahf1fo#」とコメントに記載しています。もちろん、実際に運用する時にはパスワードを違うものにします。もちろん、hashedpasswdフィールドの値を変えるのですが、例えば、以下のようなスクリプトの実行で可能です。以下は、パスワードを1234にした場合例で、実際に利用するパスワードに置き換えてコマンド実行をしてください。出力結果のハッシュ値部分を、schema_initial_data.sqlファイルにコピー&ペーストすれば良いでしょう。
% vendor/inter-mediator/inter-mediator/dist-docs/passwdgen.sh -p 1234
'','1234','3e93a6f1ae544db6b2fa3cc6cae987e158d2b138188f1f643d7db1e6a6ff9e8a456a654a'テンプレートに含まれるさまざまな仕組み
テンプレートにはサンプルとして簡単な住所録がsample_pageディレクトリにあります。このページファイルでは、Bootstrapを利用できるようにしてあります。まあ、JQuery FileUploadを使ったファイルをアップロードする仕組みも入っています。加えて、/lib/sticky-header-tableディレクトリにあるスタイルファイルを利用して、リスト表示でヘッダをページ上部に固定する設定もあります。また、/lib/utility-panelディレクトリにあるスタイルやJavaScriptを利用して、ポップアップパネルを出す仕組みもあります。単にINTER-Mediatorのサンプルというだけでなく、もう少し色々な機能を組み込んでいます。
テンプレートのレポジトリの/Accountsには、ユーザ管理のためのページがあります。このページは、adminグループのユーザしかログインできません。既定値ではadminユーザのみが利用できます。このページで、ユーザの追加や削除、パスワードのリセット等が可能です。サンプルの住所録は認証はが必要で、初期状態ではadmin、userどちらも開くことができるようになっています。認証が不要なら、/sample_page/index_contexts.phpを修正します。authemticationキーの値をコメントにすれば良いでしょう。
このアプリケーションを本番サーバで利用するときに懸念されることは、レポジトリの内容が取り出されるということです。レポジトリのルートをWebドキュメントのルートにすると、http://ドメイン名/.git 以下のGitのデータを取り出すことで、レポジトリ全体を取り出されてしまいます。レポジトリをPrivateにしても、このファイルを取り出されると中身は誰でも参照できることになります。そういうこともあって、一般にはレポジトリにはパスワード等は入れないようにということになっていますが、色々な事情でレポジトリの中に入れざるを得ない場合もありますでしょう。その場合は、.gitディレクトリをWebサーバから参照できないようにすれば良いです。その意味では、Webサーバから参照されたくないファイルはいくつもあります。例えば、YAMLやJSONで定義ファイルを作っていると、これら中身が丸見えになるのはちょっと抵抗があるでしょうし、シェルスクリプトをWeb経由で動かされるのも場合によってはサーバトラブルの原因になります。また、.sqlファイルも見られたくないものです。なお、.phpファイルはPHPが実行できる範囲であれば、大概は問題はないと思います。この対策のために、/lib/for_server/apache-deny-files.confというファイルを用意してあります。内容は執筆時点では以下のとおりです。
<FilesMatch "\.(yaml|sh|sql|json|lock|md|gitignore)$">
Order allow,deny
Deny from all
</FilesMatch>
<Directorymatch "/(\.git|MySQL_Schema|PostgreSQL_Schema)">
Order allow,deny
Deny from all
</Directorymatch>例えば、Ubuntuであれば、このファイルを、/etc/apache2/conf-availableにコピーして、「sudo a2enconf apache-deny-files」と入力すれば、設定ファイルとしてこの内容が読み込まれます。設定ファイルの内容は特定の拡張子のファイル、そしてWeb経由で読み込まれたくないファイルがあるディレクトリをそれぞれ指定したものです。もちろん、状況に応じて修正してください。また、特定のドメインだけの場合は、サイト用のファイル内に中身を組み入れるなどの対処が必要ですが、これも一種のテンプレートとしてご利用ください。
INTER-Mediatorディレクトリを非公開にする
INTER-MediatorディレクトリをWebサーバーの公開ディレクトリに置くのは危険と思われるかもしれませんが、一方で、定義ファイルエディターや、ユーザー管理のアプリケーションなどが最初から稼働しないような仕組みにしてあるので、PHPが動く状態になっていれば問題はないと考えます。params.phpファイルにデータベースのパスワード等を記述しますが、これもPHPが稼働していれば、クライアントにパスワードの文字列が漏洩することはありません。
それでも、やはりINTER-Mediator自体を非公開のディレクトリ(例えば「/usr/local/share」など)に置いて運用したいと思われるかもしれません。しかしながら、現状、一部の機能で、公開ディレクトリに存在することを前提としたものがあります。その機能を使わないのならば、Web公開ディレクトリの外部でも稼働しますが、PHPの設定等の変更は必要になる可能性もあります。
定義ファイルエディタやページファイルエディタを利用する
まず、定義ファイルエディターを使いたい場合には、可能な限り、INTER-Mediator-Server VM上で開発して、完成後に実環境に移動することをお勧めます。もし、どこかのサーバーで定義ファイルエディターを使いたくなった場合には、定義ファイル自体あるいは定義ファイルを保存するディレクトに対して、Webサーバーを稼働しているユーザーにファイル読み書きの権限を厳密に制限してセットしておく必要があります。そして、INTER-Mediatorのルートにあるeditorsフォルダーにある定義ファイルのdefedit.phpの末尾の行にあるコメントを削除してください。リスト9-5-9はdefedit.phpの最後の数行ですが、最後の行の頭にある//を削除してファイルを保存しておいてください。INTER-Mediatorのレポジトリにある定義ファイルエディターの機能は意図的に無効化してあります。有効な状態でファイルをサーバーに登録すると、それはあからさまなセキュリティホールになるからです。ここで有効化した場合は、いったんサイト全体を、Webサーバーの認証機能を利用して、ユーザー名とパスワードを入れないと使えない状態にしておくのがいいでしょう。もちろん、システム完成後はdefedit.phpの最後の行の頭に//を入れて、定義ファイルエディターを無効にしてください。そうしないと、誰もが定義ファイルを参照あるいは変更できる状態になります。定義ファイルエディタやページファイルエディタを起動するURLについては、演習環境で使っているファイル(IMApp_Trialレポジトリのルートにあるindex.phpファイル)を参考にしてください。
/**
* Don't remove comment slashes below on any 'release.'
*/
// IM_Entry($defContexts, null, array('db-class' => 'DefEditor'), false);このセクションのまとめ
INTER-Mediatorを使ったWebサイトのファイル配備の例や、params.phpファイルで置き換えの必要な箇所、そして、INTER-Mediatorをビルドして、若干の高速化を行う方法などをこのセクションで説明しました。そして、INTER-Mediatorを使ったアプリケーション開発のためのテンプレートレポジトリも紹介しました。